안녕하세요? 허니입니다. 제 글을 읽은 분이라면 컴퓨터 워드 작업을 할때면 저장 불러오기 등은 모두 해 보셨을텐데요. 이때 운영체제에서는 사용자가 모르게 많은 일들을 진행합니다. 많은 작업들은 파일시스템이라는 운영체제의 기능으로 HDD나 SSD와 같은 2차 저장소에 저장을 하여 파일을 영구 보관하게 되는거지요. 그렇다면 파일 시스템의 자세한 작업에 대해서 포스팅 해 보겠습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
![]()
파일이란 무엇인가.
![]()
파일의 구조
![]()
파일은 왜 필요한가.
![]()
파일이름의 작성
![]()
파일시스템은 왜 필요한가.
![]()
Meta data란 무엇인가.
![]()
디렉토리(Directory)란 무엇인가.
![]()
버퍼 캐쉬(butter cache)
![]()
파일 포인터의 역할...
![]()
Memory map I/O
파일이란 무엇인가?
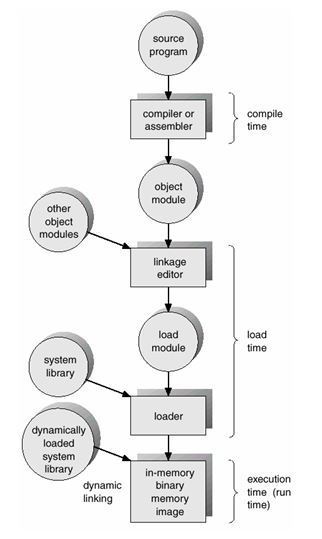
앞서 공부한 프로세스 관리나 메모리 관리에 비해 파일이라는 개념은 우리에게 좀더 익숙하게 느껴질 것이다. 그 이유는 컴퓨터 작업을 하는데 사용자에게 항상 파일이란 개념은 빠지지 않고 접할 수 있기 때문일 것이다. 그렇게 항상 익숙하게 느끼고 있는 파일이란 과연 무엇일까. 파일은 프로그램 또는 데이터 등과 같은 정보들의 집합을 말한다. 이러한 정보를 저장할 수 있는 기억장소 공간은 디스크에 할당되어 있으며 디스크에 존재하는 여러 파일들은 각자 고유한 이름을 가짐으로서 구별된다.
파일의 구조를 한번 들여다보자
파일은 ‘바이트의 연속적인 연결’이라고 정의된다. 파일의 특성을 살펴보면 파일은 바이트의 연속으로 구조가 없다. 그렇기 때문에 별다른 지정없이 파일의 시작에서 offset으로 주소지정이 가능하다. 이것은 데이터베이스의 레코드와의 구분되어지는 특성이기도한데 레코드는 필드라는 단위가 모여 이뤄지며 데이터베이스에서의 접근 단위가 되는 것이다.
필드: 데이터 항목을 의미한다. 즉 여러 개의 문자를 모아서 각 항목들의 속성을 표현하는데 사용된다. 예를 들면 이름 필드,나이필드,성별필드 등이 해당된다. |
파일은 왜 필요한가?
보고서를 하나 작성했는데 파일이라는 개념이 없다면 어떨까. 그것의 결과는 사용자에게 매우 큰 불편을 가져다주게 된다. 보고서 작성 후 컴퓨터의 전원을 컸다면 처음부터 다시 입력작업을 하는 상황이 벌어질 것이다. 파일에 관하여 사용자가 알아야 하는 것은 매우 간단하다. 바로 파일 이름 하나만 제대로 알고 있으면 어느 장소에 저장되었는지를 모른다 하여도 작업을 위해 불러올 수가 있다. 그러나 실제로 파일 하나가 생성, 수정, 저장을 거쳐 다시 불러오기까지의 작업들을 위해선 우리가 알고 있는 것 보다 휠씬 복잡한 정보들이 필요하고 복잡한 과정이 얽혀있는 것이다. 그렇기에 OS를 공부하는 사람이라면 파일 시스템을 빼 놓을 수 없는 것이다.
파일이름의 작성
파일이름이란 특정한 파일을 지칭하기 위하여 사용되는 이름을 말한다. 일반적으로 영문자와 숫자. 그리고 _ 라는 문자로 구성된다. MS-DOS에서는 8자 이내의 숫자, 문자로 파일 이름이 작성되고 WINDOW 환경내에서는 무한대로 파일이름을 작성할 수 있다.
파일시스템은 왜 필요한가?
파일시스템의 필요성을 설명하려면 먼저 파일과 디스크의 관계를 살펴보아야 한다. 파일은 정보를 저장할 수 있는 기억장소공간이 디스크에 할당되어 있으며 디스크에 존재하는 다른 파일들과 구별할 수 있는 고유의 이름이 존재한다는 것은 이미 앞서 언급하었다. 그렇다면 디스크란 무엇인가. 바로 소멸하지 않는 기억장치이다. 다시 말해 디스크에 저장된 데이터나 프로그램, 즉 파일은 프로세스가 수행을 완료하고 파괴된 후에라도 여전히 남아있게 된다. 디스크는 고정된 블록단위로 데이터를 저장하게 된다. 모든 디스크의 입력과 출력은 섹터(물리적 레코드)단위로 이뤄진다. 대부분 한 블록은 512바이트로 되어있다. 연속적인 바이트로 구성된 파일이 512바이트로 나뉘어져 디스크 곳곳에 저장되게 되는 것이다. 여기에서 드러나는 한가지 문제점은 사용자는 블록에 관한 정보를 아무것도 모른다는 점이다. 메모리는 바이트 단위로 읽어들일 수 있지만 디스크는 바이트 단위로 읽어들일 수 없는 구조로 되어 있다. 그렇기에 파일 시스템이 파일과 디스크 블록간에 밀접한 연결작업을 해주어야 한다.

그림 53 파일과 디스크
Meta data
Meta data란 파일 사용자 ID, 파일 형태, 크기, 저장장소, 정보의 장소(offset), 버퍼, 시간 정보(생성시간, 최근 읽기,쓰기된 시간)등의 정보들이 저장된 데이터를 의미한다. 바로 이렇게 파일에 접근하는데 필요한 정보를 가진 Meta data가 있어야만 파일이 제대로 관리될 수 있으며 이들은 디스크 내부에 파일과 별도로 저장된다.
디렉토리(Directory)
디스크에 저장되어 있는 파일들을 보다 효율적으로 관리하기 위하여 파일 시스템에서 사용되는 하나의 방법이 바로 디렉토리(Directory)이다. 하나의 파일시스템에서 서로 연관된 파일들을 한곳에 체계적으로 저장 될 수 있도록 하는 방법인 것이다. 여러 개의 함을 갖고 있는 서류함처럼 관련된 파일들이 저장되는 장소를 제공한다.

그림 54 컴퓨터의 디렉토리 화면
디렉토리에 대하여 실행되는 조작들은 다음과 같다.
1.탐색 : 파일의 이름들은 상호관에 연관성을 갖고 있기 때문에 특정파일을 찾기 위하여 디렉토리를 탐색하게 된다.
2.파일의 생성 : 디렉토리에 새로운 파일을 만든다.
3.파일의 삭제 : 필요하지 않는 파일들을 디렉토리에서 지운다.
4.디렉토리 열람 : 디렉토리의 내용이 되는 파일들을 보여준다.
5.예비파일복사(backup):실수로 파일들이 지워지는 상황을 고려해 여분으로 파일을 복사해둔다.
바로 디렉토리는 메타데이터를 가지고 있기에 파일들에 대한 정보를 볼수 있는 것이다. 이러한 디렉토리는 디스크안에서 파일과는 따로 관리된다.
버퍼 캐쉬(buffer cache)
버퍼 캐쉬는 파일 사용자와 디스크의 사이에 자리잡고 완충역할을 하게 되는 장치이다. 파일이 필요할 때마다 디스크에서 일일이 읽어오려면 속도가 느리다. 처음 한번 읽은 파일은 버퍼캐쉬에 내용을 카피해 둠으로서 이후 동일한 파일을 사용할 때 읽어오는 속도를 높일 수 있는 것이다. 바로 파일에 접근하는 것도 지역적 성격을 갖고 있기 때문에 버퍼캐쉬를 사용할 수 있는 것이다. 그러나 버퍼캐쉬가 무한정의 메모리를 카피할 수는 없는 것이다. 용량의 제한으로 버퍼캐쉬에 저장된 목록을 교체해야 한다. 여기에도 하나의 policy가 필요한데 앞서 메모리관리에서 배운 LRU가 일반적으로 쓰이게 되는 것이다. 이러한 버퍼캐쉬는 시스템에 하나만이 존재하는 것이다. 버퍼캐쉬상에 변화가 생기면 그 변화를 다른 장치들도 알고 있어야하기 때문이다.

그림 55 버퍼 캐쉬
파일 포인터의 역할
파일을 read/wirte 할게 될 때 파일 포인터는 현재 사용되고 있는 데이터의 위치를 알려주게 된다. 바로 현재 사용되는 offset을 파일 포인터가 나타내는 것이다.
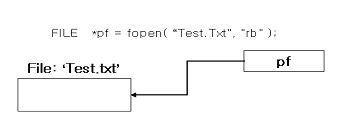
그림 56 파일 포인터
한 파일에 관한 사항은 A,B프로세스 모두가 공유할 수 있는 것이다. 그러나 offset만은 해당 프로세스가 그 파일을 현재 엑세스하고 있는 위치를 나타내고 있기 때문에 프로세스마다 다른 값을 가지게 된다. 파일을 바이트의 연속이라고 이미 설명하었다. 그렇기에 offset은 파일 처음부터 몇번째 바이트를 나타내는 정수가 된다.
Memory map I/O
디스크에 저장되어있는 파일이 버퍼캐쉬를 통해 버퍼로 read 하는 대신 주소공간에 직접 load한다. 이러한 방법을 Memory map I/O라고 한다. 즉 파일이 주소공간의 일부가 되어 파일 I/O를 하지 않고 메모리 접근을 하듯이 읽거나 쓸 수 있게 된다. 이러한 Memory map I/O를 사용하게 되면 read/write 성능을 높일 수 있다.

그림 57 Memory Map I/O 와 버퍼 환경 비교
요점정리
![]()
파일이란?
파일은 프로그램 또는 데이터등과 같은 정보들의 집합을 말한다. 이러한 정보를 저장할 수 있는 기억장소 공간은 디스크에 할당되어 있으며 디스크에 존재하는 여러 파일들은 각자 고유한 이름을 가짐으로서 구별된다.
![]()
파일의 구조는?
파일은 ‘바이트의 연속적인 연결’이라고 정의된다.
![]()
파일 시스템은 왜 필요한가?
파일은 연속된 바이트로 이뤄져 있다. 그러나 디스크는 바이트 단위로 읽어들일 수 없는 구조로 되어 있기 때문에 파일 시스템이 파일과 디스크 블록간에 밀접한 연결작업을 해주어야 한다.
![]()
Meta data란?
파일 사용자 ID, 파일 형태, 크기, 저장장소, 정보의 장소(offset), 버퍼, 시간 정보(생성시간, 최근 읽기,쓰기된 시간)등의 정보들이 저장된 데이터를 의미한다.
![]()
디렉토리(Directory)란?디스크에 저장되어 있는 파일들을 보다 효율적으로 관리하기 위하여 파일 시스템에서 사용되는 하나의 방법이 바로 디렉토리(Directory)이다. 디렉토리에 대하여 실행되는 조작들은 탐색, 파일의 생성, 파일의 삭제, 디렉토리 열람, 예비파일복사등이다.
![]()
버퍼 캐쉬(butter cache)란?
버퍼 캐쉬는 파일 사용자와 디스크의 사이에 자리잡고 완충역할을 하게 되는 장치이다. 처음 한번 읽은 파일은 버퍼캐쉬에 내용을 카피해 둠으로서 이후 동일한 파일을 사용할 때 읽어오는 속도를 높일 수 있는 것이다.
![]()
파일 포인터의 역할은?
파일을 read/wirte 할게 될때 파일 포인터는 현재 사용되고 있는 데이터의 위치를 알려주게 된다. 바로 현재 사용되는 offset을 파일 포인터가 나타내는 것이다.
![]()
Memory map I/O란?
디스크에 저장되어있는 파일이 버퍼캐쉬를 통해 버퍼로 read 하는 대신 주소공간에 직접 load하는 방법을 Memory map I/O라고 한다.
퀴즈
![]()
퀴즈1) 파일이란 프로그램 또는 데이터등과 같은 정보들의 집합을 말한다. 이러한 파일이 디스크에 할당될 때 구별되는 방법은 무엇인가.
![]()
퀴즈2) 파일의 구조와 레코드의 구조를 구분해 설명해보시오..
![]()
퀴즈3) 파일 시스템이 필요한 이유를 파일과 디스크를 연결시켜 설명해 보시오.
![]()
퀴즈4) 버퍼 캐쉬(butter cache)를 사용하게 되면 파일을 읽어오는 속도를 높일 수 있다. 그 이유를 설명해 보시오.
![]()
퀴즈5) Memory map I/O를 사용하게 되면 read/write 성능을 높일 수 있다. 그 이유는 무엇인가.
![]()
정답1) 디스크에 할당되는 여러 파일들은 각자 고유한 이름을 가짐으로서 구별된다.
![]()
정답2) 파일의 구조는 바이트의 연속으로 별다른 구조가 없으나 레코드는 필드라는 단위가 모여 이뤄진다.
![]()
정답3) 연속적인 바이트로 구성된 파일이 512바이트로 나뉘어져 디스크 곳곳에 블록 단위로 저장되게 된다. 그런데 디스크는 바이트 단위로 읽어들일 수 없는 구조로 되어있기 때문에 파일과 디스크를 연결하는 파일 시스템이 필요한 것이다.
![]()
정답4) 처음 한번 읽은 파일은 버퍼캐쉬에 내용을 카피해 둠으로서 이후 동일한 파일을 사용할 때 읽어오는 속도를 높일 수 있는 것이다.
![]()
정답5) 디스크에 저장되어있는 파일이 버퍼 캐쉬를 통해 버퍼로 read 하는 대신 주소공간에 직접 load하기 때문에 파일이 주소공간의 일부가 되어 파일 I/O를 하지 않고 읽거나 쓸 수 있게 된다. 그렇기에 Memory map I/O를 사용하게 되면 read/write 성능을 높일 수 있다.
|
목 차 |
|
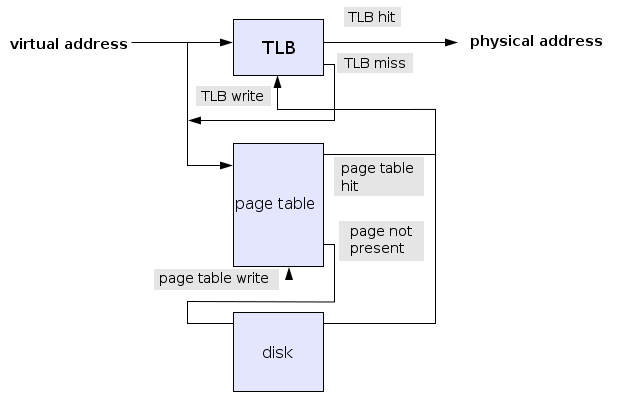
운영체제 메모리 관련해서 알아야 할 개념은 어떤것이 있나요? (TLB, Locality, Working Set, Overlay) |
|
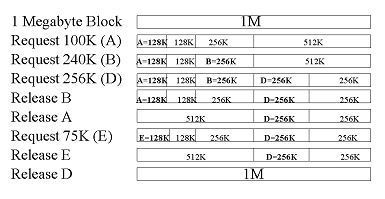
운영체제 디스크 공간 할당(Disk Space Allocation) 알고리즘과 효과적 알고리즘의 판단 기준은? |
'Past Material' 카테고리의 다른 글
| 운영체제 디스크 공간 할당(Disk Space Allocation) 알고리즘과 효과적 알고리즘의 판단 기준은? (0) | 2019.05.13 |
|---|---|
| 운영체제 파일시스템 내부구조는 어떻게 되나요? (0) | 2019.05.13 |
| 운영체제 Page replacement (페이지 대체) 알고리즘이란? (0) | 2019.05.13 |
| 운영체제 메모리 관련해서 알아야 할 개념은? (TLB, Locality, Working Set, Overlay) (0) | 2019.05.13 |
| 운영체제 Page in/out, Swapping 등이 Page Table Entry와 어떤 관계인가요? (0) | 2019.05.13 |

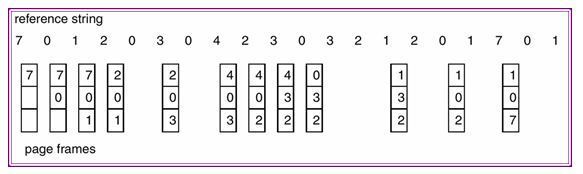
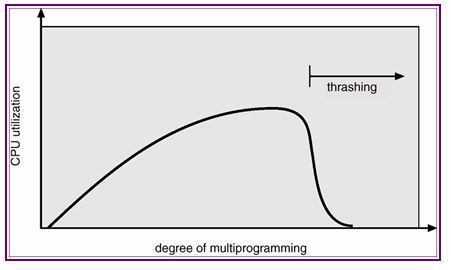






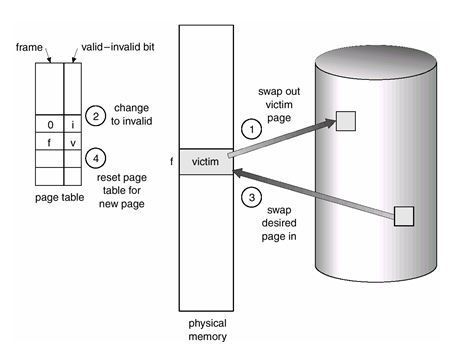

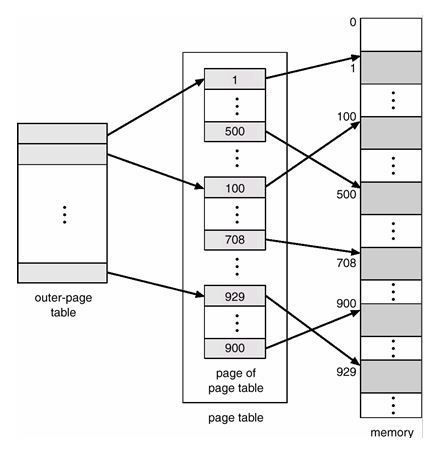




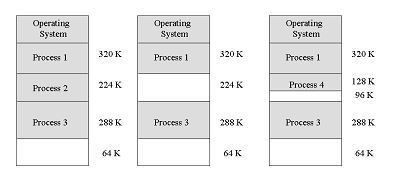
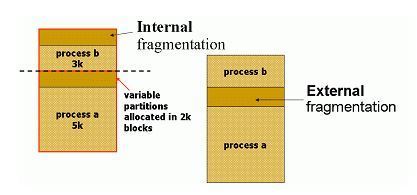

 메모리 관리(MEMORY MANAGEMENT)는 왜 필요한가.
메모리 관리(MEMORY MANAGEMENT)는 왜 필요한가.
 잠깐! 상식
잠깐! 상식