C 언어란? 상수와 기본 자료형 4.1. C 언어가 제공하는 기본 자료형 • 자료형(data type) "선언할 변수의 특징을 나타내기 위한 키워드" • 기본 자료형 기본적으로 제공이 되는 자료형 • 사용자 정의 자료형 사용자가 정의하는 자료형 : 구조체, 공용체 • 기본 자료형 종류와 데이터의 표현 범위 • 다양한 자료형이 제공되는 이유 데이터의 표현 방식이 다르기 때문 – 정수형 데이터를 표현하는 방식 – 실수형 데이터를 표현하는 방식 메모리 공간을 적절히 사용하기 위해서 – 데이터의 표현 범위를 고려해서 자료형 선택 – 작은 메모리 공간에 큰 데이터를 저장하는 경우 데이터 손실이 발생할 수 있음 • sizeof 연산자 피연산자의 메모리 크기를 반환 피연산자로 자료형의 이름이 올 경우 괄호를 사용 그 이외의 경우 괄호의 사용은 선택적 • 자료형 선택의 기준 정수형 데이터를 처리하는 경우 – 컴퓨터는 내부적으로 int형 연산을 가장 빠르게 처리, 따라서 정수형 변수는 int형으로 선언 – 범위가 int형 변수를 넘어가는 경우 long형으로 선언 – 값의 범위가 –128 ~ +127 사이라 할지라도 int형으로 선언 • 자료형 선택의 기준 실수형 데이터를 처리하는 경우 – 선택의 지표는 정밀도 – 정밀도란 오차 없이 표현 가능한 정도를 의미함 – 오늘날의 일반적 선택은 double! • unsigned가 붙어서 달라지는 표현의 범위 MSB까지도 데이터의 크기를 표현하는데 사용 양의 정수로 인식 실수형 자료형에는 붙일 수 없다. • 문자 표현을 위한 ASCII 코드의 등장 미국 표준 협회(ANSI)에 의해 정의 컴퓨터를 통해서 문자를 표현하기 위한 표준 – 컴퓨터는 문자를 표현하지 못함 문자와 숫자의 연결 관계를 정의 – 문자 A는 숫자 65, 문자 B는 숫자 66… • ASCII 코드의 범위 0이상 127이하, char형 변수로 처리 가능 char형으로 처리하는 것이 합리적 • 문자의 표현 따옴표(' ')를 이용해서 표현
4.2. 상수에 대한 이해 • 리터럴(literal) 상수 이름을 지니지 않는 상수 • 리터럴 상수의 기본 자료형 상수도 메모리 공간에 저장되기 위해서 자료형이 결정된다. • 리터럴 상수의 기본 자료형 • 접미사에 따른 다양한 상수의 표현 • 심볼릭(symbolic) 상수 이름을 지니는 상수 • 심볼릭 상수를 정의하는 방법 const 키워드를 통한 변수의 상수화 매크로를 이용한 상수의 정의 • const 키워드에 의한 상수화 • 잘못된 상수 선언
4.3. 자료형 변환 • 자료형 변환의 두 가지 형태 자동 형 변환 – 자동적으로 발생하는 형태의 변환을 의미한다. – 묵시적 형 변환이라고도 표현한다. 강제 형 변환 – 프로그래머가 명시적으로 형 변환을 요청하는 형태의 변환 – 명시적 형 변환이라고도 표현한다. • 자동 형 변환이 발생하는 상황 1 대입 연산 시 • 자동 형 변환이 발생하는 상황 2 정수의 승격에 의해(int형 연산이 빠른 이유) 정수형 연산 자체를 단일화시킨 결과 • 자동 형 변환이 발생하는 상황 3 산술 연산 과정에 의해 • 산술 연산 형 변환 규칙 데이터의 손실이 최소화되는 방향으로... • 강제 형 변환 프로그래머의 요청에 의한 형 변환
3.1. 컴퓨터 데이터 표현 • 진법에 대한 이해 n 진수 표현 방식 : n개의 문자를 이용해서 데이터를 표현 • 2진수와 10진수 10진수 : 0~9를 이용한 데이터의 표현 2진수 : 0과 1을 이용한 데이터의 표현 컴퓨터는 내부적으로 모든 데이터 2진수로 처리 • 16진수와 10진수 16진수 : 0~9, a, b, c, d, e, f를 이용한 데이터의 표현 • 데이터의 표현 단위인 비트(bit)와 바이트(byte) 비트 : 데이터 표현의 최소 단위, 2진수 값 하나 (0 or 1)을 저장 바이트 : 8비트 == 1바이트 • 프로그램상에서의 8진수, 16진수 표현 8진수 : 0으로 시작 16진수 : 0x로 시작
3.2. 정수와 실수의 표현 방식 • 정수의 표현 방식 MSB : 가장 왼쪽 비트, 부호를 표현 MSB를 제외한 나머지 비트 : 데이터의 크기 표현 • 잘못된 음의 정수 표현 방식 양의 정수 표현 방식을 적용한 경우 • 정확한 음의 정수 표현 방식 2의 보수를 이용한 음의 정수 표현 방식 • 음수 표현 방식의 증명 • 잘못된 실수의 표현 방식 정수를 표현하는 방식을 실수 표현에 적용 작은 수를 표현하는데 있어서 한계를 지님 • 정확한 실수 표현 방식 오차가 존재하는 단점을 지님, 그러나 효율적인 표현 방식
3.3. 비트 단위 연산 • 비트 단위 연산자의 종류 • & 연산자 : 비트 단위 AND • | 연산자 : 비트 단위 OR • ^ 연산자 : 비트 단위 XOR • ~ 연산자 : 비트 단위 NOT • << 연산자 : 왼쪽 쉬프트(shift) 연산 • >> 연산자 : 오른쪽 쉬프트(shift) 연산
C 언어란? 변수와 연산자편 2.1. 연산자, 덧셈 연산자 • 연산자란 무엇인가? 연산을 요구할 때 사용되는 기호 ex : +, -, *, /
2.2. 데이터 저장을 위한 변수 • 변수란 무엇인가? 데이터를 저장할 수 있는 메모리 공간에 붙여진 이름 • 다양한 형태(자료형)의 변수 정수형 : char, int, long 실수형 : float, double • 변수의 선언 및 대입 대입 연산자(=): 값을 대입하기 위한 용도의 연산자 • 변수를 이용한 예제 • 변수 선언 시 주의 사항 1 변수를 함수 내에 선언할 경우, 등장 위치! • 변수 선언 시 주의 사항 2 첫째 : 변수의 이름은 알파벳, 숫자 언더바(_)로 구성 둘째 : 대 소문자 구분 셋째 : 변수의 이름은 숫자로 시작 불가, 키워드 사용 불가 넷째 : 공백이 포함될 수 없음 • 완성된 덧셈 프로그램 • 변수와는 다른 상수! 상수도 메모리 공간을 할당 받는다. 하지만 데이터의 변경이 불가능하다.
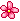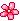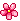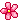
2.3. C 언어의 다양한 연산자 • 대입 연산자와 산술 연산자 • 기타 대입 연산자 대입 연산자와 산술 연산자가 합해져서 다양한 형태의 대입 연산자 정의 • 부호 연산으로서 +, - 연산자 단항 연산자로서 +, - • 증가 감소 연산자 • 관계 연산자(비교 연산자) 두 피연산자의 관계(크다, 작다 혹은 같다)를 따지는 연산자 true(논리적 참, 1), false(논리적 거짓, 0) 반환 예제 op6.c, 표 3-4 참조 • 논리 연산자 and, or, not을 표현하는 연산자 true(1), false(0) 반환 • 비트 단위 연산자 ~, &, ^, |, <<, >> • 콤마(,) 연산자 둘 이상의 변수 동시 선언 시 둘 이상의 문장을 한 줄에 선언 시 함수의 매개변수 전달 시 • 연산자의 우선 순위 연산 순서를 결정짓는 순위 • 연산자의 결합성 우선 순위가 같은 연산자들의 연산 방향
2.4. scanf 함수의 이해 • scanf 함수를 이용한 정수의 입력 • scanf 함수를 이용한 입력 형태의 지정 입력 형태의 지정이 가능
안녕하세요? 허니입니다. 오늘부터 C 언어에 대해 작성해 보려고 합니다. C 언어는 프로그래밍을 시작하는 초보 개발자들이 입문하는 언어로 C 언어 외에도 파이썬, C++, JAVA 등 언어는 많습니다.(: 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
C 언어란? C 언어 이야기 & 프로그램 기본 구성 1.1. C 언어 이야기 • 프로그래밍 언어란 무엇인가? 사람과 컴파일러가 이해할 수 있는 약속된 형태의 언어 C 언어도 프로그래밍 언어 중 하나이다. • 컴파일이란 무엇인가? 프로그래밍 언어로 작성된 프로그램을 컴퓨터가 이해할 수 있도록 기계어로 번역해 주는 역할을 하는 번역기 • C 언어의 장점 익숙해지는데 오랜 시간이 걸리지 않는다. 이식성이 좋다. 효율성이 높다. • C 언어의 단점 프로그래밍 하는데 많은 주의를 요한다. 완전한 고급 언어에 비해 상대적으로 어렵다.
1.2. 프로그램의 완성 과정 • 프로그램 작성 및 실행 순서 1. 프로그램 작성 2. 컴파일 3. 링크 4. 실행파일 생성
1.3. 프로그램의 기본 구성 “Hello, World” • 함수에 대한 이해 적절한 입력과 그에 따른 출력이 존재 하는 것을 가리켜 함수라 한다. C 언어의 기본 단위는 함수이다. • 함수 호출과 인자 전달 인자 전달 : 입력 x를 전달하는 행위 함수 호출 : 인자를 전달하면서 함수의 실행을 요구하는 행위 • C 언어의 함수 특성 입력과 출력 존재 순차적으로 실행 함수의 기능을 정의하는 몸체 부분 존재 • 예제 Hello.c에서의 함수 • 세미콜론이 필요한 문장 연산을 수행하는 문장 : 시간의 흐름에 따라서 컴퓨터에게 "이러 이러한 일을 해라"라고 명령을 하는 문장 • 표준 라이브러리에 대한 이해 이미 표준화 해서 만들어 놓은 함수들의 집합을 가리켜 표준 라이브러리라 한다. 헤더 파일을 포함해야 사용이 가능하다. • 헤더 파일의 이해 stdio.h 라는 이름의 헤더 파일 헤더 파일의 포함을 알리는 선언은 제일 먼저 등장해야 한다. • return의 의미 함수를 종료(빠져 나온다). 함수를 호출한 영역으로 값을 반환 • return의 특징 return은 함수 내에서 존재 하지 않을 수도 있다. 둘 이상의 return문이 존재하는 것도 가능
1.4. 주석에 대한 이해 • 주석이란? 프로그래머에게 메모(memo)의 기능을 부여 컴파일러는 주석을 없는 것으로 간주 주석을 삽입 함으로 인해 프로그램의 가독성 증가 선택이 아닌 필수! • 주석의 두 가지 형태 여러 줄에 걸친 주석 처리 단일 행 주석 처리 • 주석의 예 • 주석 처리에 있어서의 주의점 주석을 나타내는 기호는 중복될 수 없다. 단, 단일 행 주석은 중복 가능하다.
1.5. printf 함수의 기본적 이해 • printf 함수 사용의 예 1• printf 함수 호출의 이해 1 • printf 함수 호출의 이해 2 : 서식 문자 서식 문자(Conversion specifier)란 출력 대상의 출력 형태를 지정하기 위한 문자 • printf 함수 호출의 이해 3 • printf 함수 사용의 예 2 • printf 함수 호출의 이해 4
안녕하세요? 허니입니다. 운영체제 아키텍처의 종류와 그 내용을 가지고 포스팅 하려고 합니다. 운영체제의 종류는 정말 많은데요. 아무 대부분이 아시는 윈도우, 리눅스 운영체제는 모놀리식 운영체제이며 임베디드 관련된 운영체제는 계층적 또는 마이크로 운영체제를 많이 쓰고 있습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
운영체제 아키텍처
모놀리식 운영체제 (Monolithic Operating System)
계층적 운영체제 (Layered Operating System)
마이크로커널 운영체제 (MicroKernel Operating system)
현대 운영체제는 많은 서비스를 제공하고 다양한 하드웨어, 소프트웨어 자원을 지원하기 때문에 매우 복잡하다. 운영체제 설계 연구자들은 운영체제 구성 요소를 구성하고 각 구성 요소가 실행될 권한을 지정할 수 있게 함으로써 이러한 복작성을 해결합니다. 모놀리식 설계에서 운영체제의 모든 구성 요소를 커널에 포함하지만 마이크로 커널 설계에서는 필수 구성 요소만 커널에 포함시켜 안정성을 최대화 하였습니다.
모놀리식 운영체제
가장 초기에 개발된 보편적인 운영체제 설계며 모든 구성 요소를 커널에 포함시킨 아키텍처이다. 단순히 기능 호출만으로도 다른 구성요소와 직접 통신이 가능하며 이런 유형의 커널은 컴퓨터 시스템에 제한없이 접근해 실행할 수 있다.
그림 1. 모놀리식 운영체제 커널의 아키텍처 & 마이크로커널 운영체제 아키텍처
그림에서 보듯이 모놀리식 커널은 구성 요소들을 함께 그룹화하기 때문에 모놀리식 운영체제의 구성 요소 간 직접적인 상호 통신은 효율을 높여준다. 그러나 버그의 원인이나 기타 오류를 구분하기 어려워 안정성에 문제가 있다. 더욱이 모든 코드가 제한없이 시스템에 접근하므로 모놀리식 커널 시스템은 특히 오류나 악성 코드나 해킹로부터 해를 입기 쉽다.
계층적 운영체제
운영체제가 점점 커지고 복작해짐에 따라 순수한 모놀리식 설계는 점점 다루기 어려워졌다. 이 문제를 해결하기 위해 운영체제에 대한 계층적 접근법이 시도되었다. 계층적 접근법은 유사한 기능을 수행하는 요소들을 구룹으로 묶어 계층으로 구분하며 각 계층은 오직 바로 위아래에 잇는 계층과 상호 작용 할수 있다. 하위 계층은 구체적인 구현을 숨긴채 인터페이스를 통해 상위 계층에 서비스를 제공한다. 계층적 운영체제는 모놀리식 운영체제보다 모듈화가 잘 되어 있다. 다른 계층에 전혀 영향을 주지 않고 각 계층의 구현을 수정할 수 있기 때문이며 모듈화된 시스템은 시스템 전반에 걸처 재사용할 수 있는 자기 충적적인 구성 요소들이 포함된다.
그럼 2. 운영체제의 계층적 구조
각 구성 요소는 작업을 수행하는 내부적인 방법을 감추고, 표준 인터페이스를 보여줌으로써 다른 구성 요소들이 서비스를 요청할 수 있게 한다. 모듈화는 운영체제에 구조와 일관성을 부여하며 소프트웨어 검증과 디버깅 및 수정 과정을 간편하게 해준다. 그러나 계층적 접근법은 사용자 프로세스의 요청을 수행하는데 많은 계층을 거쳐야 하며 한 계층에서 다음 계층으로 데이터를 전달할 때마다 추가적인 함수 호출이 발생하므로 모놀리식 커널에 비해 성능이 많이 떨어진다.
마이크로커널 운영체제
마이크로커널 운영체제 아키텔처는 커널의 규모를 최소화하고 규모 확장성을 높이고 필수 서비스만 제공한다. 여기에 포함되는 서비스는 전형적으로 수준이 낮은 메모리 관리, 프로세스 간 통신, 프로세스 간 협력을 위한 기본적인 동기화 기능뿐이 없다. 이 설계에서는 프로세스 관리, 네트워크, 파일 시스템 상호 작용과 장치 관리 등 대부분의 운영체제 구성 요소를 커널이 아닌 유저 권한을 통해 커널 외부에서 작동한다. 마이크로 커널은 모듈화 정도가 높아서 확장성, 이식성, 규모 확상성이 높다. 더 나아가 실행을 위해 각 구성 요소에 의존하지 않기 때문에, 한두개 구성요소에 오류가 발생하여보 운영체제 전체가 마비되지 않는다. 그러나 이러한 모듈화는 모듈 간 통신 정도가 높아지므로 성능 저하가 나타나는 트레이드 오프가 있다.
그 외 운영체제
그 외로 네트워크 운영체제, 분산 운영체제, 하이퍼바이저 운영체제 등 많은 아키텍처들이 존재한다.
안녕하세요? 허니입니다. 오늘은 운영체제 가상메모리에 대해 자세하게 포스팅 하려고 합니다. 운영체제에서 가상 메모리는 매우 중요한 개념입니다. 대부분 이 부분을 자세히 모르기 때문에 운영체제 공부하는데 많은 어려움이 있는 것으로 알고 있습니다.
오늘의 주제
가상 메모리
가상메모리는 1950년대 메모리의 부족, 즉 실행 화일이 메모리보다 더 큰 문제를 해결하기 위해 overlay와 같은 기법을 활용하였지만 많은 문제점을 야기하였습니다. 가상메모리는 메모리 부족 문제에 대한 훌륭한 해법이 되었고, 1960년대에 상업용 운영체제에 적용되어 쓰이게 됩니다. 이후 쓰레싱(Thrashing)이라는 문제점에 대해서 1970년대 후반 워킹셋(Working-Set)을 이용한 해결책이 나오게 되었습니다. 가상메모리의 기본적인 개념은 "가상주소(Virtual Address)"와 "물리주소(Physical Address)"의 분리입니다. 즉, 10번지의 내용물과 20번지의 내용물을 더해서 30번지에 넣으라는 명령어 (Instruction)에 대해서 기존에는 10,20,30이라는 주소는 메모리의 실제 주소(physical address)였다면, VM은 10,20,30이 가상 주소(virtual address)입니다. 따라서 실제로 메모리의 어느 지점의 내용물들이 사용될런지는 이것만으로는 알 길이 없습니다. 따라서 VM을 구현하기 위해서는 MMU(Memory management unit)이라는 CPU내의 특수한 하드웨어가 필요합니다. 이 unit에 의해서 10,20,30이라는 virtual address는 100,200,300 따위의 실제 주소(physical address)로 변환됩니다. 이러한 변환과정(mapping)은 매우 중요합니다. 아시다시피, 그렇지 않아도 빠른 CPU를 따라오지 못하는 메모리 속도가 문제가 되는 시점에서, 1번의 메모리 참조(reference)를 매번 이와 같은 변환 과정을 거쳐서 참조해야 한다는 것은 막대한 성능의 저하를 초래할 것이기 때문입니다. 그렇다면 이러한 성능의 저하를 감수하고라도 가상메모리 기능을 이용할 필요가 있는 것인가? 그렇습니다. 그에 따르는 수많은 장점들이 있기에 현대 CPU가 대부분 이를 사용하겠지요. 그렇다면 맵핑(mapping) 과정에서 일어나는 부하를 최대한으로 줄이는 것이 관건이 됩니다. 이를 위해 사용되는 것이 TLB(Translation Look-aside Buffer)입니다. 가상메모리의 강력함은 그 부수적인 효과에서도 대단한 변화를 가지고 왔습니다. 즉, 가상메모리로 인하여 각 프로세스는 자신만의 4GB라는 거대한 주소 공간을 가지게 된 것입니다. 이 공간은 다른 프로세스에게 보이지 않기 때문에 자신만의 공간이며, 4GB라는 풍족한 주소 공간을 활용하여 이전에는 생각하지 못했던 일들을 할 수 있습니다.
위 그림은 리눅스에서 초기 프로세스의 메모리 맵입니다. 첫 번째 줄에서 0804800 지점에 초기 실행 파일이 올라와 있고, 그외 ld-2.3.2.so 나 libc-2.3.2.so 같은 이미지들이 올라와 있습니다. 이처럼 4GB라는 주소공간이 바로 가상 메모리 주소입니다. 여기에 속한 메모리의 크기는 무려 4GB씩이나 되니 알 수 있는 것이 init이라는 이미지는 ld 와 libc라는 또 다른 이미지들을 사용하고 있다는 것을 알 수 있습니다. ld는 dynamic linker입니다. 즉, 공통으로 사용되는 libc를 init에서 사용하는데, 이 library를 동적으로 불러 주는 것이 ld라는 linker입니다. 이 ld 는 일반적으로 compiling에 사용되는 static linker이기도 하지만, 동시에 dynamic linker로도 쓰이며 또한 dynamic library라는 또 다른 특징이 존재합니다.
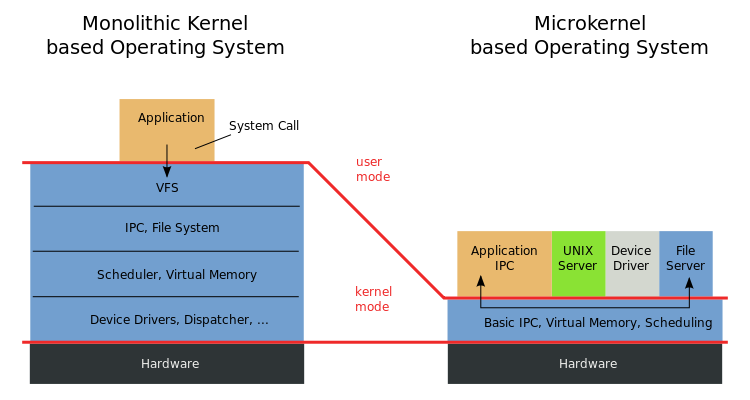
Figure 3-12는 인텔에서 제공하여 가지고 온 그림입니다. 인텔 구조에서 linear 주소라고 불리기도 하는 가상주소를 물리 주소로 변환하는 과정을 보여주는 그림입니다. 가상 주소는 3부분으로 나뉘는데, 가장 뒤 12비트는 offset으로서 아무런 변환도 거치지 않습니다. 앞의 10비트는 page directory에서의 index를 나타내는 부분으로 쓰이고, 중간의 10비트는 page table에서의 index를 나타내는 부분으로 쓰입니다. 또한, CPU 내 page directory를 가리킬 하나의 레지스터가 필요합니다. 인텔에서는 CR3라는 레지스터가 있어, 이 레지스터가 Page directory의 주소를 가지고 있게 됩니다. 문맥 교환이 일어나서 다른 프로세스의 가상 주소 공간로 전환하려면 이 CR3의 내용을 해당 프로세스의 page directory의 주소로 넣어줌으로써 각 가상 주소 공간 간의 전환을 하게 됩니다. 앞 포스팅에서 설명했듯이 물리 메모리는 모두 4KB의 단위의 page로 구성되었다고 생각하고, 이러한 page 단위로 접근하기 때문에, 모든 단위는 page로 이루어지는 것이 좋습니다. 따라서 위의 page table과 page directory는 모두 1 page를 차지하게 됩니다. 또한 각 entry는 4byte로 이루어지기 때문에, 자연히 1개의 page는 (위에서 각 page directory와 page table은) 1024개의 entry를 가지게 됩니다. offset은 변환이 완료된 물리 page 안에서 offset만을 나타내기 때문에 아무런 변환이 없이 사용될 수 있습니다. 이제 하나의 메모리 참조를 하기 위해서는 CR3가 가리키는 페이지에서 가상 주소의 앞 10비트를 index로서 사용해서 해당하는 entry를 참조합니다. 10비트이기 때문에 정확히 1024개의 entry를 사용하게 되는 것입니다. 이렇게 얻은 4byte자리 entry는 다시 다음 page table로의 base address를 제공하게 됩니다. 이때 다시 중간의 10bit를 index로서 사용하여, 역시 10bit이기 때문에 1024개의 entry를 사용하게 되고, page-table entry를 얻게 됩니다. 이때 나오는 page-table entry가 비로소 물리 page의 물리적 주소를 제공하게 됩니다. 이 주소에 원래 가상 주소의 마지막 12bit를 합쳐주면 최종적인 물리 주소를 얻게 됩니다. 이러한 과정은 다음 그림과 같은 2-level tree로서 구성해서 이해할 수 있습니다.
그림에서 보듯이 CR3를 root로 해서 tree 구조를 형성하고 있습니다. CR3를 제외한 하나의 사각형은 모두 4KB짜리 페이지를 나타냅니다. 따라서 하나의 사각형당 최대 1024개의 화살표를 가질 수 있습니다. 위의 그림에서 page directory에서부터 각 level에서 가상 주소의 각 10비트씩을 index로 사용하여 최종 단계로 가서 실제 물리 Page의 주소를 얻게 됩니다. 이렇게 얻은 주소에 12bit의 offset을 합치면 물리 주소가 됩니다. 여기서 사각형 안에 있는 번호는 물리 page number임을 주의하시기 바랍니다. 실제 개념도는 tree로 표현하였지만 page directory와 page table등은 모두 실제 메모리를 차지하는 하나의 page이기 때문에 실제로는 각 번호대로 일렬로 그려야 할 것입니다. 이러한 실제 메모리에 대한 그림을 뒤에 넣었으니 참조하시기 바랍니다. 하나의 page table은 1024개의 entry를 가지고, 한 개의 entry가 한 개의 page를 가리키기 때문에, 하나의 page table은 1024개의 page를 가리킬 수 있습니다. 역시 한 개의 page directory에 의해서 1024개의 page table을 가리키기 때문에, 하나의 page directory는 총 1024*1024개의 page를 가리킬 수 있게 됩니다. 이는 곧 4GB의 공간을 나타낼 수 있습니다. 하지만 실제로 이 모든 맵핑을 한다면, page directory와 page table을 위해서 1025개의 page를 소모하는 꼴이 됩니다. 대략 4MB의 용량입니다. 하나의 프로세스가 이 맵핑을 위해 4MB씩을 소모할 수는 없기 때문에 필요로 하는 부분만을 맵핑하여 사용합니다. 위의 그림에서 12번 물리 페이지를 사용하는 page directory는 4개의 화살표만을 가지고 있습니다. 이것은 곧, 5번째 이후의 entry들은 null일테고, mapping이 존재하지 않는다는 뜻입니다. 즉, 해당 가상 주소에 대한 가상 주소 공간가 존재하지 않는다는 것입니다. 한 개의 page directory entry는 1개의 page table에 대응하고, 하나의 page table은 4MB를 커버하기 때문에, 4개의 화살표는 0~16MB의 공간을 뜻합니다. 위 그림에서는 16MB까지만의 가상 주소만 유효한 것으로 생각하시면 됩니다. 다시 말해 Page table에서도 모든 화살표가 있는 것이 아니기 때문에, 화살표가 있는 부분만이 유요한 주소공간이라고 할 수 있습니다. 그렇다면 유효하지 않는 주소 공간으로 접근하게 되면 어떻게 될까요? 이런 경우에는 당연 page fault가 발생합니다.
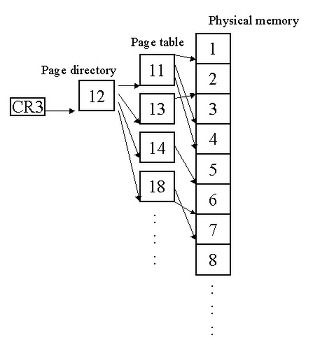
위 그림에서 확인하듯이 page table entry입니다. 각 페이지 디렉토리나 페이지 테이블은 이와같은 엔트리를 1024개씩 가지게 됩니다. 물론 가장 중요한 정보는 다음 단계로의 포인터역할을 하는 기본 주소이고, 그외에 Read/Write bit은 해당 페이지가 read-only일지를 결정하고, User/Supervisor bit은 해당 페이지를 유저 공간에서 접근가능한지 아니면 커널모드에서만 접근가능한지를 나타냅니다. 그외에는 Access bit이 있는데 해당 페이지가 접근되면 1로 세팅됩니다. 또한 Dirty bit은 해당 페이지가 쓰이면 1로 세팅됩니다. 이러한 비트들은 CPU가 1로 세팅하며 절대 0으로 세팅하지는 않고, 운영체제 만이 0으로 세팅합니다. 운영체제는 이러한 CPU가 주는 정보를 다양한 방식으로 이용하게 됩니다.
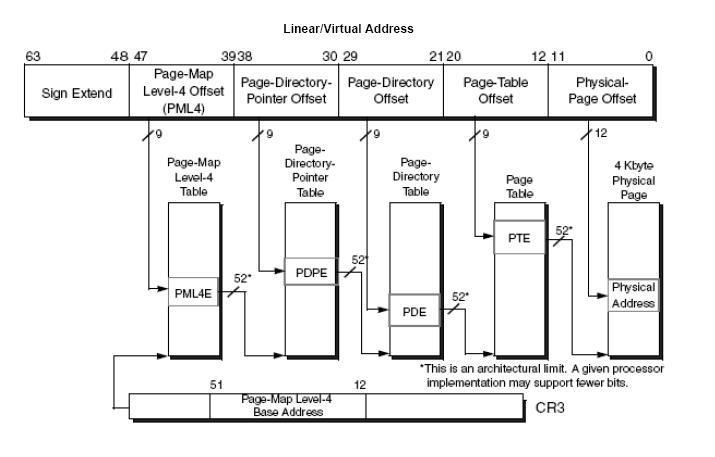
위의 그림은 64비트의 경우입니다. 32bit의 경우를 확장한 것인데, 처음 4G의 물리메모리가 부족해지자 인텔은 PAE(Physical address extension)이라는 이름으로 물리 주소를 36비트로 확장하고, page table구조를 바꾸게 됩니다. 각 엔트리는 크기가 2배로 늘어 한 페이지안에는 512개의 엔트리만이 들어가게 되었습니다. AMD가 이 구조를 약간 확장하여 하나의 level을 더 추가하여 64비트에서도 계속 사용합니다.
Page Table Structure 가상메모리의 페이지 매핑을 구현하는데에는 보통 위와같이 tree 구조를 사용합니다. 하지만 그외에도 다양한 방식들도 있습니다. PDP-11에서는 레지스터에 page table을 두기도했지만, 이건 작은 페이지 테이블이었기에 가능합니다. 그외에 Hashed Page Table이 있습니다. Offset을 제외한 가상 주소가 해쉬함수로 들어가서 linked list를 찾아들어가 스캐닝하면서 찾아갑니다. 이 리스트안의 엔트리는 virtual page number, physical page number, pointer to next element in the list 등으로 이루어집니다. 순차적으로 virtual page number를 비교해가며 찾는거죠. 그외에 Inverted Page Table이 있습니다. 이경우엔 거꾸로 각 physical page마다 하나의 엔트리를 가집니다. 그리고 여기에 해당 페이지로의 virtual address들을 넣습니다. 따라서 시스템전체에 하나의 페이지 테이블만이 있게되죠. 검색을 위해서는 보통 ASID를 사용합니다. 그래서 offset이외의 부분과 ASID를 가지고 page table을 검색해서 그 index를 physical page number로 사용하게됩니다. 64비트 UltraSPARC과 PowerPC가 이런방식을 사용합니다. 메모리 사용량은 줄겠지만 그러나 검색에 시간이 듭니다. 전체 테이블을 끝까지 검색할수도 있죠. 이를 위해서는 앞서서의 hashed page table방식을 도입해 합칠수도 있겠습니다. 어떤 아키텍쳐의 경우엔 TLB miss handler도 있습니다. TLB가 미스났을때 불리우는 핸들러로 운영체제가 직접 TLB를 채워주는것입니다. x86의 경우엔 하드웨어가 Page table을 읽은후에 직접 TLB에 값을 채워넣죠. 이 방식이 빠르고 간편한 반면 페이지 테이블의 구조가 하드웨어에 의해 정해진다는 점이 있습니다. HW-defined page table라고도 불리며 x86과 PowerPC가 그렇습니다. 반면 운영체제가 TLB미스를 처리하는경우는 SW-defined page table이라고 합니다. UltraSparc, MIPS, Alpha가 그렇습니다. 이 경우는 오버헤드가 있지만 수정이 가능합니다.
안녕하세요? 허니입니다. 운영체제에서 가장 중요하다고 말할수 있는 인터럽트에 대해 리눅스 기반으로 자세히 포스팅 하려고 합니다. 예전 포스팅에서도 인터럽트에 대한 설명이 있었습니다. 간단하게 인터럽트가 뭐지? 정도만 알고 싶으면 이전 포스트를 보시면 더 편하실꺼라고 생각합니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
인터럽트(Interrupt)
인터럽트 컨트롤러(Controller)
인터럽트 벡터(Vector)
CPU 보호(Protection)
현대 컴퓨터는 대부분 Interrupt-driven 기법으로 인터럽트를 활용합니다. 이 기법은 정상적인 프로그램의 실행 도중 발생한 사건을 해결하기 위해 잠깐 다른 부분을 실행한 이후에 다시 원래 실행하던 것을 계속해서 실행합니다. 대표적으로 I/O처리로 외부 장치들과 의사소통하기 위해서 Interrupt라는 방식을 사용합니다. 이 Interrupt는 CPU가 정신없이 일하고 있을 때, IO 장비들이 당장 작업이 필요할 때 Interrupt라는 신호를 줌으로써 CPU에게 알리는 것입니다. 이와 대조적으로 예전 Apple같은 경우 Polling이라는 방식을 썼었습니다. 이 방식은 CPU가 한 명령어(Instruction)이 끝날 때마다 I/O 적업을 검색하여 작업할 I/O가 있는지를 살펴보는 기법이었습니다. 매우 비효율적이라고 할 수 있습니다. 당연히 Interrupt 방식이 효율적입니다. 그 반대급부로 Interrupt는 구현이 복잡하다는 단점이 있습니다. 구현이 간단한 Polling의 경우, 먼저 스캔하는 IO 슬롯이 자연히 높은 우선 순위를 가지게 됩니다. Interrupt의 경우 우선순위는 하드웨어적으로 어떻게 Interrupt를 구현하느냐에 달려있습니다. CPU의 pin들중에 하나에 interrupt request있습니다. I/O 장비들 중에서 interrupt가 일어나면 이 line에 신호가 걸리게 되고, CPU는 machine cycle을 돌던중에 마지막에 이러한 신호를 체크하게 됩니다. 이때 interrupt가 있다면 interrupt handler로 제어를 옮깁니다.
Interrupt가 들어왔을 때 처리해주는 코드를 interrupt handler라고 합니다. CPU는 interrupt가 들어오면 이 interrupt handler를 실행한후에 언제 그랬냐는 듯이 다시 이전 프로그램을 실행합니다. wmr, 현재 실행중인 프로그램을 방해하지 않으면서 효과적인 I/O 성능을 달성합니다. real mode에서는 상대적으로 이러한 interrupt의 처리가 간단하였습니다. CPU는 interrupt가 오면 주소 0번에서부터 시작하는 interrupt vector table을 참조하여 해당 주소로 점프하기만 하면 되었습니다. 이와같이 I/O device가 필요할 때 CPU에게 interrupt를 걸 수 있지만, 때로는 이러한 interrupt들을 무시해야할 때가 있습니다. 이럴 때 cli 와 같은 instruction을 사용하면 IO장비들로부터 오는 interrupt를 무시할 수 있습니다. 이것을 interrupt disable한다고 합니다. 반대로 sti instruction에 의해서 다시 interrupt enable할 수 있습니다. 그러나 이 명령들이 모든 종류의 interrupt들을 무시하게 해주는 것은 아닙니다. instruction에 의해서 무시될 수 있는 interrupt들을 maskable interrupt라고 하고, 그렇지 않는 것들을 non-maskable interrupt라고 합니다. 인텔 CPU에는 INTR pin말고도 NMI pin이 있습니다. 이것은 nonmaskable interrupt의 신호가 들어오는 pin입니다. power failure같은 interrupt는 매우 중요한 interrupt이기 때문에 NMI에 속합니다. 즉, 무시할 수 없는, cli/sti instruction에 영향을 받지 않는 interrupt입니다. Maskable interrupt와 NMI외에도 CPU내부에서 발생하는 예외처리가 있으며 외부에서 발생하는 interrupt들과는 달리 CPU내부에서 발생하는 신호들입니다. instruction을 실행하다가 만나게 되는 문제점들에 대해서 CPU가 스스로 발생시키는 신호인 것입니다. 즉, 예외처리는 항상 instruction과 동기화되어 발생한다는 점 때문에 synchronous interrupt 라고 부르기도 하고, 반대로 NMI와 maskable interrupt를 IO장비에서 아무때나 전달되어오는 신호이기 때문에 asynchronous interrrupt라고 부르기도 합니다.
Asynchronous interrupt
Maskable interrupt
INTR pin으로 들어옴.
cli/sti 로 금지시킬 수 있다.
IO장비에서 오는 모든 인터럽트들.
NMI
NMI pin으로 들어옴.
Synchronous interrupt
exception
CPU내부에서 발생. page fault등.
interrupt라는 용어가 어떤 경우에는 이 3가지 종류의 신호들을 모두 가리키기도 하고, 때로는 exception을 강조하여 interrupt는 maskable interrupt와 NMI만을 뜻하기도 합니다. 주로 과거에 interrupt라는 단일 용어로 쓰였었는데, 386이후부터는 VM등의 영향으로 CPU의 control unit이 내부적으로 처리해야할 상황이 많아지면서 (각종 fault들) 최근에는 exception과 interrupt를 구분해서 쓰이는 경향이 있습니다. 이 포스팅에서도 exception와 interrupt를 구분하여 쓰도록 하겠습니다만, 가끔 그렇지 못한 경우도 있지만 이전 포스팅을 보셨다면 어렵진 않으니 문맥을 보고 잘 판단하시기 바랍니다. 예외처리나 인터럽트가 걸리면 기본적으로 CPU는 자신이 현재 실행중이던 곳의 주소인 EIP를 스택 (커널 모드 스택)에 저장하고, 해당 인터럽트나 예외를 처리합니다. 인텔 매뉴얼에서는 exception을 이 저장되는 EIP의 값에 따라서 다음과 같이 정의하고 있습니다.
- fault : fault란 발생한 사건을 복구하고 다시 재시작할 수 있는 상황들입니다. 따라서 이 경우 스택에 저장된 EIP에는 fault를 발생시킨 해당 instruction을 가리키고 있습니다. 따라서 fault handler가 끝나고 복귀할 때는 해당 instruction을 다시 실행하게 됩니다. 현대의 CPU들은 이러한 이유로 실행하다가 중지된 instruction을 undo 하는 기능을 가지고 있습니다. (나중에 더 자세히 살펴볼 기회가 있을지...) 대표적으로 page fault를 생각할 수 있습니다. - trap : trap은 해당 instruction이 종료되어서 다시 실행될 필요가 없는 경우, 그 다음 instruction의 주소를 스택에 넣게 됩니다. 따라서 이 trap을 처리한후 돌아와서는 그 다음 instruction을 실행하는 것입니다. 대표적인 용도로 디버깅을 들 수 있습니다. 매 instruction이 끝나고나서 그 결과를 보기 위해서 사용될 수 있습니다. 또는 breakpoint의 설정등에 사용됩니다. - abort : 이것은 심각한 에러로 인하여 더 이상 진행이 될 수 없는 상황에서 발생합니다. 이때는 스택의 eip에는 의미없는 값이 저장될 수도 있고, 프로세스가 종료되어야만 하는 상황입니다.
이외에 INT instruction에 대해서도 알 필요가 있습니다. INT(interrupt)라는 명령어는 소프트웨어에서 직접 예외처리하거나 interrupt를 일으킬 수 있게 해주는 명령입니다. 이것은 system call을 구현할 때와 같은 경우에 필수적으로 필요한 기능입니다. 이런 경우를 인텔 매뉴얼에서는 Software-generated interrupts라고 하고 있습니다. 이 부분에 대해서는 뒤에서 좀더 자세히 살펴보도록 하겠습니다.
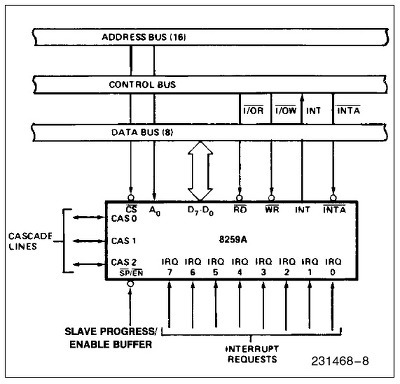
Interrupt controller PC에서는 interrupt의 구현을 위해서 인텔 8259A 칩을 사용합니다. 이러한 칩을 PIC (programmable interrupt controller) 라고 하는데, 이 PIC의 역할은 다른 device controller로부터 interrupt신호를 받아 우선순위가 높은 신호를 CPU에게로 전달해주는 것입니다. 키를 눌렀다든지 타이머 시간이 다 되었다든지, DMA전송이 끝났다거나 패킷이 도착하는 등 인터럽트로 들어옵니다. device가 IRQ선에 신호를 주면 PIC은 vector를 I/O port에 쓰고, INTR핀을 통해 CPU에 인터럽트를 보냅니다. 그리고 CPU가 ack하기를 기다렸다가 INTR선을 clear합니다.
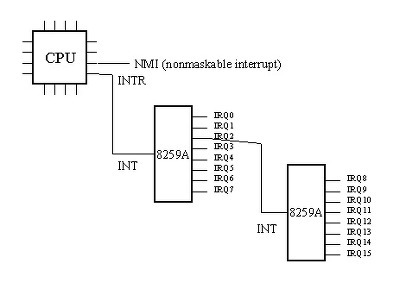
original PC나 XT에서는 하나의 8259칩을 사용하였는데, 위의 그림에서 보시다시피, 최대 8개까지의 장치를 연결할 수 있었습니다. 8259A 는 이들을 직렬연결(cascade)을 통해 최대 64개의 장치까지를 연결할 수 있게 되어있습니다. AT이후부터는 이 8259A 2개를 연결하여 총 16개의 interrupt를 처리하고 있습니다. 여기서 눈여겨볼 pin은 IRQ0부터 IRQ7까지의 외부 device controller와 연결되는 IRQ선과, CPU의 INTR pin에 연결되어 interrupt를 요청하는 INT선, 그리고 CPU로부터 interrupt에 대한 ack를 받는 INTA pin입니다. 개념적으로 나타내면 다음과 같이 그릴 수 있습니다.
위에서 PIC 2개를 직렬연결(cascade)하였음을 볼 수 있습니다. 8259A 칩은 priority에 따라서 IRQ선으로 오는 신호를 처리하기 때문에, 위의 예에서의 우선순위는 0,1,8,9,10,..14,15,3,4,5,6,7 임을 알 수 있습니다. 또 다른 NMI pin은 nonmaskable interrupt를 받는 pin입니다. PIC은 또한 CPU에게 어느 장치가 interrupt를 일으켰는지를 알려줄 interrupt vector를 넘겨주어야 합니다. 이것을 위해서 PIC는 들어온 선의 신호를 미리 지정된 번호(interrupt vector)로 바꾸어 IO공간에 써넣게 됩니다. 보통 많은 OS들이 PIC을 초기화할때 보통 IRQ선 번호+32 를 씁니다. 즉, IRQ0번은 32번 interrupt vector에 해당합니다. 0에서 31번까지는 인텔이 exception을 위한 번호로 쓰기때문에 충돌을 피하기 위함이죠. 이러한 IRQ와 vector간의 mapping은 PIC에 입출력 명령을 써서 programming할 수 있습니다. 이제 8259A의 동작을 살펴봅시다. 8259A는 IRR(Interrupt Request Register) 라는 레지스터를 가지고 있습니다. 이 레지스터는 8bit로 이루어져있으며, 각 bit는 각 IRQ선에 대응됩니다. 어느 한 IRQ선에서 신호가 들어올 때, 정확히는 신호의 rising edge가 파악되었을 때 해당 bit는 1이 됩니다. 또다른 8bit의 IMR(Interrupt Mask Register) 라는 레지스터는 각 IRQ선에 대해서 개별적으로 masking을 할 때 사용됩니다. IRR과 not(IMR)을 AND시킴으로써 masking이 이루어 집니다. 또한 ISR(In Service Register)라는 8bit의 레지스터가 있습니다. 이 register는 들어온 interrupt가 CPU에게 전달되었을 때 (CPU에서 INTA선을 타고 ack가 왔을 때) 1이 되고, CPU가 EOI (End of Interrupt)신호를 보내올 때 0이 됩니다. IRR에 있는 요청들중에서 우선순위가 가장 높은 것이 ISR에 전달되는것입니다. 즉, ISR에 있는 '1'은 해당 interrupt를 CPU가 처리중임을 표시합니다. 따라서 우선순위가 낮은 IRQ선에서 신호가 들어올 때, ISR의 그보다 높은 bit들중 '1'이 있을 때 그 interrupt의 처리는 미루어집니다.
1. ISR, IRR, IMR 이 모두 0입니다. 2. IRQ3에 신호가 실립니다. 3. IRR의 3번째 bit가 '1'이 됩니다. 4. IMR의 3번째 bit가 0이므로, IRR의 3번째 bit는 다음 회로의 input으로 들어갑니다. 5. ISR의 모든 bit가 0이므로, 즉, 처리중인 더 높은 우선순위의 interrupt가 없으므로, INT선에 신호를 줍니다. 즉, CPU의 INTR선에 신호가 들어갑니다. 6. CPU는 INTR의 신호를 감지하고 INTA신호를 줍니다. 7. IRR중 가장 높은 우선순위가 3번 bit이므로 ISR의 3번째 bit를 set합니다. 8. CPU가 두 번째 INTA신호를 줍니다. 9. ISR의 가장 높은 3번 bit에 해당하는 interrupt vector를 IO공간에 씁니다. 10. INT신호를 끄고, IRR의 3번째 bit는 0으로 reset합니다. 11. 이후에, CPU는 처리를 마친후 EOI 신호를 주고, 이것은 ISR의 3번째 bit를 reset합니다.
예를 들어보면 IRQ 1,2,5번 이 발생했을때 IRR은 00100110 이 되고 이중 우선순위가 가장 높은 1번 IRQ가 IMR에도 안걸리기때문에 ISR로 전달됩니다. 만약 IMR에 걸렸더라면 IRQ2번이 전달되겠죠. 만약 ISR에 0번 IRQ가 처리중이라면 ISR로 전달되지 못하겠지만, 그렇지 않다면 ISR로 전달됩니다. 예를들어 현재 ISR이 01000000 로서 6번 IRQ를 처리중에 있다면 1번IRQ가 전달된후에 01000010 이 됩니다. 물론 PIC에서 이루어지는 masking은 각 IRQ선에 대해서 개별적으로 이루어질 수 있습니다. 이 masking은 cli에 의한 CPU의 interrupt disable과는 별개입니다. 또한 EOI역시 주의하세요. 인터럽트 핸들러는 EOI를 전달하여야 합니다. 그렇지 않다면 ISR에 여전히 처리중으로 남게되고 IRR의 그보다 우선순위가 낮은 인터럽트들은 ISR로 전달되지 못하게 됩니다. 보통 IRET전에서 EOI를 보내주죠. 더 자세한 내용은 8259A data sheet를 참조하시기 바랍니다. 요즘같은 MP환경에서는 인터럽트 처리를 위해서 APIC을 사용합니다. APIC은 멀티코어등의 mp머신들을 위한 인터럽트 처리 시스템입니다. 인텔환경에서는 각 코어는 LAPIC (local apic)을 가지고, 전체 시스템은 외부 인터럽트를 처리하는 하나이상의 IO apic을 가집니다. 외부 인터럽트는 IO apic을 통해서 local apic으로 전달되는 구조죠. 특이할만한 사실은 local apic은 각 CPU별로 접근이 된다는것인데, 즉 해당 물리메모리주소가 CPU-local이라는 얘깁니다. (디볼트로 0xFEE00000 에서 시작하는 local apic영역) 그래서 이 같은 주소에 접근하더라도 각 CPU는 자신만의 CPU번호를 가져오게되고, 이것이 CPU번호로 쓰일수 있습니다. 물론 IO apic은 일반적인 다른 메모리와 같이 모든 코어에 대해 global합니다. 참고로 첫번째 IO apic의 주소가 0xFEC00000 입니다. apic은 IO port를 가지지 않으며 이 영역에 직접 값을 읽고써서 접근합니다. 8259A는 이제 IO apic에 연결되어서 인터럽트를 처리하게 됩니다. IO apic은 전달받은 인터럽트를 어느 CPU에 전달할지등을 결정하게 되는 것이죠. lapic은 또한 IPI를 처리하는데도 쓰이고, 타이머도 가지고 있지요.
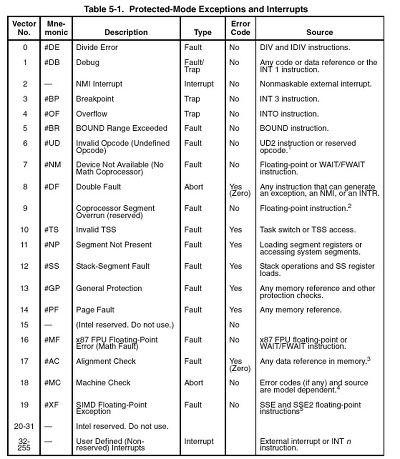
Interrupt vector 이러한 모든 interrupt나 exception들은 0에서 255까지의 숫자로 구분됩니다. (할당됩니다.) 이러한 숫자를 interrupt vector라고 부릅니다. PC에는 interrupt vector table이 있어서 이 table에서 각 interrupt가 들어올 때 그것들에 대한 vector번호를 가지고 처리할 handler의 주소를 얻을 수 있게 되어있습니다. (386이후에는 기본적으로 같지만 좀더 복잡합니다.) 따라서 모든 interrupt나 exception들은 vector값을 가지고 있으면서, 해당 interrupt나 exception이 발생하면 vector table에서 handler의 주소를 찾아서 실행하게 되는 것입니다. 다음 테이블은 각 interrupt나 exception에 vector번호가 어떻게 할당되어있는지를 보여줍니다.
여기서 0부터 31번까지의 vector 번호가 예약되어 있음을 볼 수 있습니다. 이중 2번에 NMI가 할당되어 있음을 알 수 있습니다. 즉 NM와 exception은 0~31번에 할당되어 있습니다. 따라서 maskable interrupt들은 32번 이후로 매핑이 가능합니다. 이러한 매핑은 APIC을 통해서 변경할 수 있게 됩니다. 따라서 OS에 따라서 매핑은 차이가 날 수도 있는 것입니다. Linux의 경우 IRQ번호+32번 vector에 각 IRQ들을 할당하고 있습니다. 즉 32번은 IRQ 0 번에 할당되어있는 것입니다. x86에서는 예외를 20여개정도 일으키는데, 각 경우마다 CPU의 동작이 조금씩 차이가 나기도 합니다. 이를 좀 살펴보면, 위의 표에서 알아두어야할 주요 exception은 #GP, #PF 정도입니다. 13번 #GP의 경우 intel의 protected mode에서의 보호정책을 위반하였을 때 일어나는 exception으로 이 표에 들어가지 못한 온갖 잡다한 에러들의 경우가 모두 포함되는, 쉽게말해 그외의 모든경우들..이라고 할수 있겠습니다. 윈도우에서 자주보던 General Protection Violation입니다. :-P 또 14번 #PF는 우리 눈에 익은 page fault입니다. 가상메모리에 관련하여 이 page fault와 그 handler를 잘 이해하는 것이 중요합니다. #SS는 원래 세그멘테이션 관련하여 자라나는 스택에 대한 exception인데 리눅스와 같이 세그멘테이션을 쓰지 않는다면 볼일이 없겠군요. 리눅스에서는 그런 경우 역시 모두 #PF로 처리됩니다. 하지만 이와 같이 스택이 넘치는 경우, 혹은 자라나는 스택에 대한 처리등을 통해서 VMA를 더 잘 이해할 수 있을 것입니다. #GP를 비롯해 많은 예외들이 SIGSEGV로 처리되는것을 볼수 있습니다. 디버깅 관련해서는 #DB와 #BP가 있습니다. 각각 보통 single-step exception 과 break point exception 이라고도 불리는데, 둘다 SIGTRAP이라는 시그널로 전달되는것을 알수 있죠. 이전에 하드웨어적인 지원이 없을때 int3 명령으로 (#BP) 디버거를 구현했었습니다. (물론 지금도 유효) int3이 한바이트짜리 명령이라 해당 지점의 명령의 op코드를 이 int3로 바꿔치기해넣는 방식이었는데, 이후에 HW지원이 들어오면서 새롭게 #DB가 추가되었습니다. 그래도 호환성이나 유용성등의 이유로 여전히 #BP도 많이 쓰죠. 이 두 예외와 다른 디버깅 레지스터들이 디버거에 의해서 사용됩니다. 이런 디버깅 레지스터들이 instruction breakpoint와 data breakpoint를 둘다 지원하며 이런 지원이 없을때 instruction breakpoint구현하기는 좀 곤란한데, 코드를 수정해야 하기 때문이죠. 그런 방법으로도 불가능한 것이 ROM과 같은 영역에 대한 instruction breakpoint인데, 그래서 또한 이러한 하드웨어 지원이 필요합니다. 4개까지의 주소를 지원하는데, 가상주소를 가지는 DR0부터 DR3까지 레지스터가 debug address register, DR4, DR5는 reserved, DR6는 status register, DR7은 control register입니다. 그외의 자원으로는 EFLAGS의 Single-step flag (TF), Resume flag(RF), 그리고 잘 안쓰지만 TSS의 Trap bit도 있습니다. 물론 이런 자원들은 모두 privileged입니다. breakpoint와 별도로 single-stepping을 지원하는 것을 볼수 있네요. 아직 많은 디버거들이 op-code를 patch하는 방식으로 int3을 끼워넣어서 instruction breakpoint를 구현하는것 같습니다. 이 방법으로 하면 모든 쓰레드가 해당 포인트에 hit한다는점이나 watchpoint는 구현할수 없다는것등이 제약점이 됩니다. 반면 HW를 활용한다면 기본적으로 쓰레드당 break point를 설정하게 된다는점과 watchpoint의 구현이 쉽다는것등이 좋은점입니다. 이러한 exception들은 리눅스 등 유닉스 시스템에서는 보통 현재 process에게로 전달됩니다. exception의 경우 현재 실행중이던 process에서 발생한 것이기 때문에 interrupt와 달리 현재 process에게 signal을 보내는 것으로 처리할 수 있습니다. 그렇게 함으로써 해당 process가 처리하도록 하기 때문에 커널입장에서는 exception은 손쉽고 빠르게 처리할 수 있습니다. 이처럼 예외의 경우, 커널은 signal로 해당 process에게 전달해주기 때문에 상대적으로 쉽고 빠르게 처리할 수 있지만, interrupt의 경우는 그렇지 않습니다. 왜냐하면 exception과는 달리 interrupt는 일어난 시점의 실행중이던 process와 아무런 관련이 없고, 전달된 interrupt를 해당 process에게 전달해주어야 하기 때문입니다. 이런 이유로 interrupt처리는 좀 더 복잡해집니다.
CPU Protection 이러한 인터럽트중에서 중요한 것으로 timer interrupt가 있습니다. timer정도가 뭐가 중요하냐고 반문하실지 모르겠지만, 이 timer interrupt 기능은 multitasking을 위한 기본적인 조건으로 HW는 일정한 시간간격마다 interrupt를 발생시킬 수 있어야 합니다. 그래야만 time sharing system 을 구현할 수 있기 때문입니다. 즉 우리는 OS가 항상 control 을 가질수 있게끔해야하는데, 그래야 user가 무한루프에 빠졌을때도 OS가 시스템을 유지할수 있으니까요, 이를 위해 필요한것이 timer 입니다. 이를 통해 CPU를 보호하는거죠. 당연히 타이머를 조작하는 명령도 priviledged입니다. 보통 타이머가 0번 IRQ죠. 그만큼 중요합니다. 타이머얘기가 나온 김에, 쉬운듯 쉽지않은 타이머의 세계를 들여다 봅시다. 먼저 HW적인 clock source를 살펴봅니다. (1) Real-time clock (RTC) 오래된 방식이죠. 전원이 나가있을때도 동작하고 물론 wall-clock입니다. 그리고 Programmable Interval Timer (PIT), (2) HPET, RTC보다 높은 resolution을 제공 (3) APIC, APIC 타이머 (4) time stamp counter (TSC)는 cpu cycle을 이용한 방식 등이 있습니다. TSC 경우 cpu안에 cycle을 세는 64bit register가 있고 이 값을 읽어오게 됩니다. 가장 resolution이 높다는 장점이 있는 반면, 멀티코어나 SMP와 같은 현대의 환경에서는 각 코어별로 skew가 존재한다는 점때문에 각 코어간의 시간을 비교할때에는 보정이 필요합니다. 또한 DVS와 같은 cpu frequency를 바꾸는 기술을 쓴다면 역시 그것도 고려한 보정이 필요합니다. 또한 타이머는 아닌 단순 clock source입니다. 이처럼 각 소스는 각각 장단점과 resolution, 그리고 SW에게까지 전달되는 방식이 있습니다. 이렇게 전달된 타이머 이벤트가 실제로 응용프로그램에 전달되기까지 여러 계층을 거쳐서 올라가게 됩니다. 당연히 여기에서 delay가 발생합니다. 그렇기 때문에 여러 계층에 따라서 자신이 가질수 있는 timer resolution이 달라지게 됩니다. 물론 커널은 (혹은 hypervisor)는 직접적으로 타이머를 이용할수 있지만 어플리케이션은 다릅니다. 예를들어 리눅스에서 setitimer로는 HRT없이는 jiffie의 한계 아래로는 내려갈수가 없습니다. 또한 심지어 이벤트가 사라질수도 있습니다. 가상화환경이라면 물론 운영체제 조차 timer resolution이 커지게 됩니다. hypervisor가 event를 전달하는 과정이 끼어들기 때문이죠. 따라서 컴퓨터가 가진 모든 종류의 timer event라는것들은 정확히 그 시간에 발생하는것이 아니며, 단지 지정된 시간이 지난후에 발생한다는점만이 보장될뿐입니다. 따라서 유저레벨에서 여러 타이머 이벤트의 skew나 lost를 경험하는 것은 흔한 일입니다. 이런 논의에서 볼수 있듯이, 기계가 시간을 다룬다는 것은 무척 어려운 문제가 됩니다. 따라서 real-time과 같은 특수한 영역이 생깁니다.
Vector no.
Mnemonic
Linux의 handler
설명
Signal
0
#DE
divide_error()
DIV나 IDIV가 0으로 나누려고 하거나 결과값이 표현하기에 너무 클 때 발생
SIGFPE
1
#DB
debug()
eflags의 TF 플래그가 설정되는등의 디버깅을 위한 exception조건들이 있을 때 발생합니다.
SIGTRAP
2
nmi()
NMI
3
#BP
int3()
INT3 명령으로 발생하는데, 보통 디버거가 breakpoint를 만들기 위해 삽입해 넣습니다.
SIGTRAP
4
#OF
overflow()
INTO명령은 EFLAGS의 OF플래그가 켜져있을 때 overflow가 발생하면 이 exception을 발생시킵니다.
SIGSEGV
5
#BR
bounds()
BOUND명령이 operand가 주소 범위를 벗어났을 때 발생시킵니다.
SIGSEGV
6
#UD
invalid_op()
잘못된 op-code일때.
SIGILL
7
#NM
device_not_available()
x87 FPU, MMX,등의 장비가 사용준비가 되지 않았을때
SIGSEGV
8
#DF
double_fault()
CPU가 예외를 처리하는 중인데 예외가 다시 발생했을 경우. 보통 이런 경우 둘을 serial하게 처리할 수 있지만, 간혹 그럴 수 없는 경우가 발생하는데, 이런 경우에 발생.
SIGSEGV
9
coprocessor_segment_overrun()
최근 인텔의 프로세서에서는 발생하지 않지만, 예전 386에서만 387에서 문제가 발생했을 때 발생
SIGFPE
10
#TS
invalid_tss()
TSS가 잘못되었을 때.
SIGSEGV
11
#NP
segment_not_present
segment descriptor나 gate descriptor의 present flag가 꺼져있는 경우. 즉 존재하지 않는 세그먼트를 참조하는 경우에 발생
SIGBUS
12
#SS
stack_segment()
존재하지 않는 stack segment를 SS레지스터에 load하려는 경우거나 스택 세그먼트의 한계를 넘어서는 경우.
SIGBUS
13
#GP
general_protection()
보호모드에서 보호 규약을 어겼을때.
SIGSEGV
14
#PF
page_fault()
주로 참조하는 주소에 대한 페이지가 없거나 하는등의 paging 매커니즘의 규약을 어겼을때
SIGSEGV
15
(인텔이 예약)
16
#MF
coprocessor_error()
CR0의 NE flag가 켜져있을 때 발생하는데, x87 FPU가 에러를 발견했을 때 발생.
안녕하세요? 허니입니다. 운영체제 파일시스템에서 Access time, 디스크 스케줄링을 위한 알고리즘, I/O 시스템에 대해서 포스팅 하도록 하겠습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
접근 시간(Access time)
seek time
rotational delay time
transfer time
디스크 스케줄링을 위한 알고리즘
FCFS
SSF(Shortest Seek Time First Scheduling) 최단 탐색 시간 우선 스케줄링
Scan algorithm
Look
I/O 시스템이란 무엇인가?
Access time
앞서 우리는 read/write 명령문을 통해 필요한 데이터가 어디에 위치해 있는지를 확인하게 되면 access arm에 부착된 read/write 헤드는 해당 데이터가 위치한 디스크공간을 찾아가 명령문을 처리하게 된다고 공부하었다. 그렇다면 read/write 명령을 받은 후 헤드가 이동하여 데이터를 전송하는데 쓰이는 시간, 즉 access time은 어떻게 계산되는 것일까. 이러한 access time은 탐색시간(seek time), 회전지연시간(rotational delay time), 전송시간(transfer time)의 각각의 3단계로 나뉘어지게 된다.
탐색시간(seek time)이란 read/write 헤드를 데이터가 저장되어 있는 트랙위치로 이동시키는데 소요되는 시간을 말한다. 디스크 상에 인접한 실린더를 탐색하게 되는 최소거리 이동시간과 최대거리 이동시간을 고려한 평균으로 탐색시간은 계산된다. 디스크마다 차이가 있지만 보통 20ms 정도의 시간이 걸린다.
회전지연시간(rotational delay time)이란 read/write 헤드를 데이터가 위치하는 트랙으로 이동시킨 순간부터 원하는 섹터에 헤드가 다다를 때까지 소요되는 시간을 의미한다. 즉 디스크가 도는 속도에 따라 회전지연시간은 차이가 나지만 보통 회전지연시간은 3200rpm이 소요된다.
전송시간(transfer time)이란 read/write 헤드가 찾은 데이터를 실제로 디스크로부터 사용자의 버퍼로 보내지는데 소요되는 시간을 의미한다. 보통 1바이트를 전송하는데 0.1마이크로 세컨이 걸린다.
디스크 스케줄링
앞서 access time의 3가지 각기 다른 구성시간을 살펴보았는데 이중 탐색시간이 가장 많은 시간을 소요한다는 것을 발견한 시스템 설계자들은 탐색시간을 최소화하기 위해 디스크 내부에서 헤드를 어떻게 스케줄링 할 것인지 연구하게 되었다. 바로 수십, 수백 개의 데이터를 찾는 요구가 떨어졌을 때 어떻게 디스크 스케줄링을 해야만 최소의 시간에 가장 많은 데이터를 처리할 수 있을까를 생각하게 된 것이다. 디스크 스케줄링은 FCFS (First Come First Service), SSF(Shortest Seek Time First Scheduling), Scan algorithm, Look등의 방법이 있다.
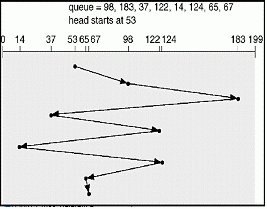
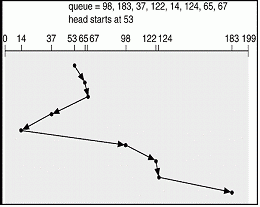
FCFS (First Come First Service) 선도착 선처리 FCFS는 요구가 들어온 순서대로 헤드를 움직이는 방법이다. 이 방법의 가장 큰 장점은 프로그래밍하기 간단하고 사용자들에게 공평하다는 것이다. 먼저 요구되어진 데이터를 가장 먼저 찾는다면 불만을 표시할 사람은 없을 것이다. 그러나 불만이 없다고 하여 그것이 최선의 방법일 수는 없다. FCFS의 방법은 데이터 처리 요구가 상호 연관성이 없기 때문에 임의로 해드가 움직여야 한다. 예를 들어 번호가 0부터 99인 100개의 트랙이 있다고 하자. 다음과 같은 순서로 (12, 45, 80, 16, 30) 데이터를 찾는 요구가 발생했을 때 헤드의 이동 거리를 계산해보자.
바로 요구 순서에 맞춘 두 개의 데이터 사이에 거리가 멀수록 디스크 헤드의 이동 거리가 멀어져 암의 이동시간도 회전지연시간도 길어질 수밖에 없는 것이다. 이러한 문제에 부딪힌 시스템 설계자들은 다음과 같은 방법을 고안해 내었다.
SSF(Shortest Seek Time First Scheduling) 최단탐색시간 우선스케줄링 SSF는 현재 헤드의 위치로부터 가장 가까운 실린더에 놓인 데이터를 먼저 처리하는 방법이다. 바로 FCFS의 커다란 단점이었던 헤드의 이동거리를 SSF 알고리즘에서는 최소화하게 되는 것이다. 12에서 45로 이동하기 전에 중간에 위치한 16과 30을 처리하게 되면 탐색시간(seek time)을 FCFS에 비해 단축할 수 있다.
FCFS에서와 같은 예를 이용해 실제 계산을 한번 해보자. (12, 45, 80, 16, 30)
FCFS와 SSF 두가지 방법의 헤드 이동거리 계산 결과를 비교해보면 그 차이를 실감할 수 있을 것이다. 그러나 SSF 방법도 하나의 커다란 문제점을 지니고 있다. 12로 부터 가장 멀리 떨어진 80은 가장 늦게 처리되었다. 80으로 헤드를 이동 시키기 전에 계속해서 요구되어진 데이터들이 22, 33, 7, 15, 4에 위치해 있다면 헤드가 80으로 향하는 시간은 계속해서 멀어질 수 밖에 없다. 바로 현재 헤드가 놓인 위치로부터 최단거리에 놓인 데이터들이 계속해서 요구되어지는 경우가 발생하면 무한정 기다림을 갖는 데이터가 생기게 되는 것이다.
Scan algorithm 스캔 알고리즘은 헤드가 한번은 디스크의 안쪽 끝에서 바깥쪽 끝으로 한번은 바깥쪽 끝에서 안쪽 끝으로 이동하면서 요구된 데이터를 처리하는 것이다. 만약에 새로운 데이터의 요구가 현재 헤드가 이동중인 방향으로 놓이게 되면 처리될수 있다. 그러나 헤드의 뒤쪽에 놓이게 되면 디스크 끝까지 헤드가 이동된후 다시 되돌아 올때까지 기다리게 된다. 우리가 엘리베이터를 이용할 때 1층에서 승차한 사람이 12층을 올라가기 위해 버튼을 눌렀다고 생각해보자. 그 이후 바로 5층에서 한사람이 내려가는 버튼을 눌렀다하더라도 엘리베이터는 5층을 무시하고 1층에서 12층까지 올라간다. 그리고 다시 12층에서 내려올때 5층에 서게 된다. 5층에서 엘리베이터를 기다리는 사람(데이터)은 12층까지 올라갔다 다시 내려오는 엘리베이터를 기다리야 하는 것이다. 이렇듯 엘리베이터 작동과 유사한 특성 때문에 스캔 알고리즘을 엘리베이터 알고리즘이라고도 부른다.
앞서 예를든 것과 동일한 경우를 생각해보자. (12, 45, 80, 16, 30)
헤드가 가장 안쪽에서 바깥쪽으로 먼저 스캔하게 된다면 0부터 헤드가 이동하여 12, 16, 30, 45, 80의 데이터를 처리하고 트랙의 가장 바깥쪽까지 스캔하게 된다. 만약 30을 처리한 직후 28 위치에 데이터가 요구된다면 헤드의 이동방향과는 다른 요구이기 때문에 바깥쪽 끝까지 스캔이 끝난후 다시 안쪽끝으로 스캔할 때 처리되어 지는 것이다.
그림 66 Scan Algorithm
스캔 알고리즘은 탐색시간(seek time)의 단축을 가져왔다는 점과 SSF에서 발생한 무한정의 기다림을 갖는 데이터를 방지했다는 것이 장점이다. 그러나 헤드가 항상 디스크 안쪽끝과 바깥쪽 끝을 스캔하기 때문에 헤드의 이동거리가 요구된 데이터들의 간격보다 넓어지는 것이다. 바로 디스크 바깥쪽 끝에 요구된 데이터가 없을 경우 헤드는 괜한 걸음을 하게 되는 것이니까.
Look algorithm 스캔알고리즘이 갖고 있는 단점을 해결하기 위한 고안된 방법이 바로 룩 알고리즘이다. 주어진 데이터 요구값에 가장 작은 번호부터 가장큰 번호까지 처리하는 방법이다. 앞서 예를든 것과 동일한 경우를 생각해보자. (12, 45, 80, 16, 30)의 데이터가 요구된다면 12부터 80까지 헤드가 이동되는 것이다. 바로 헤드가 12의 데이터 요구를 처리한 다음 무작정 이동방향을 따라 움직이는 것이 아니라 또다른 요구데이터가 있는지를 확인한 다음 이동하게 되는 것이다. 그렇게 되면 12, 16, 30, 45, 80까지 처리한 이후 이동방향으로 더 이상 요구데이터가 없음이 확인되면 더 이상 이동하지 않는다. 바로 요구된 데이터가 있는지 없는지를 계속해서 'Look'하며 이동하는 것이다.
그림 67 Look Algorithm
I/O시스템이란 무엇인가?
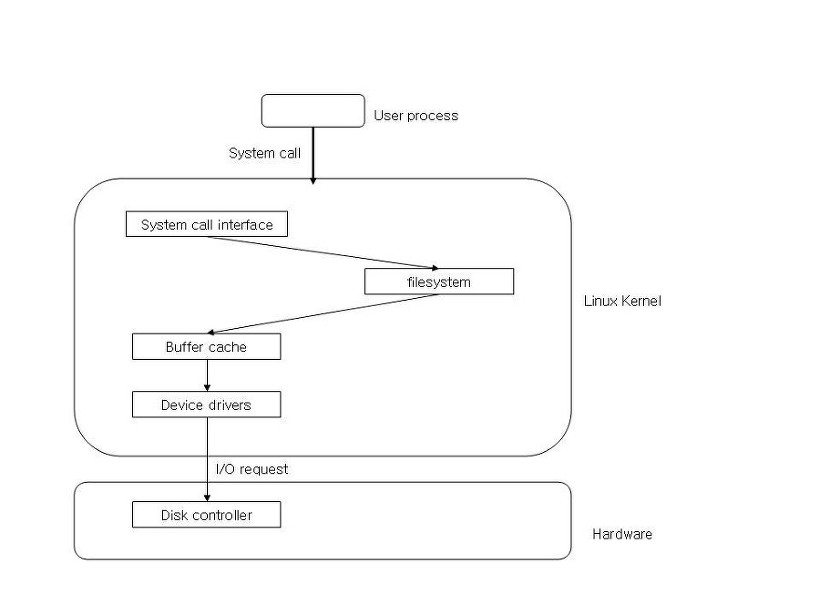
기존에 컴퓨터에 새로운 프린터를 추가해 연결 할 때 컴퓨터본체에 코드를 꽂는다고 작동될까. 윈도우 환경에서 사용할 경우 새 하드웨어 추가라는 목록으로 가서 새로운 프린터를 등록해야만 이용이 가능하다. 이런 것을 처음 경험한 사람들이라면 누구나 당혹스러워했을 것이다. 이러한 당혹스러움은 바로 I/O시스템을 공부함으로 해결 될 수 있다. 지금까지 우리가 배워온 모든 영역들은 시스템 내부적인 것 들 이었다. 그러나 I/O시스템은 사용자가 직접 접하게 되는 영역이다. I/O시스템이 작동되기까지는 다음과 같은 과정들을 거친다.
그림 68 I/O 시스템의 구조
I/O시스템은 커널을 통해 명령받게 된다. 이러한 명령들은 계속해서 쏟아져 나올 때 커널은 어느 명령을 먼저 처리할 것인지에 관해 조절기능을 하게 된다. 이렇게 하나의 명령이 주어지면 장치구동기(Device driver)를 통해 추가 명령이 실행될 주변장치를 제어, 관리하게 되고 이어 장치제어기(Device controller)를 통해 실행 하드웨어가 작동되는 것이다.
잠깐, 상식!
장치제어기(Device controller)란... 입출력장치를 컴퓨터시스템버스에 접속하기 위하여 사용하는 입출력장치의 인터페이스제어장치를 말하고 이것의 기능은 컴퓨터 시스템을 구성하는 각각의 장치에서 정상적인상태로 작업을 진행할 수 있도록 제어하고 관리하는 것이다
장치구동기와 장치제어기는 하나의 하드웨어에 각각 하나씩 존재한다. 모니터, 모뎀, 키보드, 프린터 등이 각자만의 장치구동기를 갖고 있다는 말이다. 그렇기에 새로운 프린터를 추가할 경우 단지 본체에 젝을 꽂는다는 것만으로 프린터가 작동되지 않는 것이다. 시스템내부에 새로운 프린터를 작동시키는 역할을 맡게될 장치구동기와 장치제어기를 설정해야하는 것이다. 이렇듯 여러 I/O장치들이 각각 장치구동기를 갖는 이유는 뭘까. 키보드가 1초에 처리하는 데이터양과 모뎀이 1초에 처리하는 데이터의 양이 같다면 이 둘은 하나의 장치구동기를 사용하여도 된다. 결국 각각의 I/O장치마다 서로 다른 특성을 가졌기에 그 특성을 뒷받침 해줄 장치구동기가 필요한 것이다. 새로운 하드웨어가 기존 시스템에 추가될 수 있는 것은 장치구동기를 커널과 연결시킬 수 있는 장치가 커널에 존재하기 때문이다. 바로 장치구동기와 커널 사이에는 연결을 위한 상호간에 대화통로인 디바이스인터페이스가 정의되어 있는데 지원되는 기능이 이미 정의되어 있다. 그렇기에 커널이 내부적으로 어떻게 운영되는지 모르는 사람도 I/O 시스템을 사용할 수 있는 것이다.
장치구동기(Device driver)를 특성에 따라 분류
block device driver란?
최소단위를 갖고 고정된 크기의 데이터를 읽고 쓰는 장치구동기를 말하는 것으로 디스크와 CD-ROM등이 이에 속한다.
character device driver란?
고정된 크기가 사용자의 자유에 따라 임의 크기의 데이터를 읽고 쓸 수 있는 장치구동기를 말한다. 터미널과 마우스등이 character device driver에 속한다.
요점 정리
Access time의 구성 1)탐색시간(seek time)이란 read/write 헤드를 데이터가 저장되어 있는 트랙위치로 이동시키는데 소요되는 시간을 말한다. 2)회전지연시간(rotational delay time)이란 read/write 헤드를 데이터가 위치하는 트랙으로 이동시킨 순간부터 원하는 섹터에 헤드가 다다를때까지 소요되는 시간을 의미한다. 3)전송시간(transfer time)이란 read/write 헤드가 찾은 데이터를 실제로 디스크로부터 사용자의 버퍼로 보내지는데 소요되는 시간을 의미한다.
디스크스케줄링의 방법 1) FCFS (First Come First Service) 선도착 선처리 FCFS는 요구가 들어온 순서대로 헤드를 움직이는 방법이다. 2)SSF(Shortest Seek Time First Scheduling) 최단탐색시간 우선스케줄링 SSF는 현재 헤드의 위치로부터 가장 가까운 실린더에 놓인 데이터를 먼저 처리하는 방법이다. 3)Scan algorithm 스캔 알고리즘은 헤드가 한번은 디스크의 안쪽 끝에서 바깥쪽 끝으로 한번은 바깥쪽 끝에서 안쪽 끝으로 이동하면서 요구된 데이터를 처리하는 것이다. 4)Look algorithm 주어진 데이터 요구값에 가장 작은 번호부터 가장 큰 번호까지 처리하는 방법이다.
I/O시스템이란? I/O시스템은 커널을 통해 명령받게 된다. 이러한 명령들은 계속해서 쏟아져 나올 때 커널은 어느 명령을 먼저 처리할 것인지에 관해 조절기능을 하게 된다. 이렇게 하나의 명령이 주어지면 장치구동기(Device driver)를 통해 추가 명령이 실행될 주변장치를 제어, 관리하게 되고 이어 장치제어기(Device controller)를 통해 실행 하드웨어가 작동되는 것이다.
디바이스 커널 인터페이스란? 바로 장치구동기와 커널 사이의 연결을 위한 상호간에 대화통로로 지원되는 기능이 이미 정의되어 있다.
장치구동기(Device driver)의 분류 1)block device driver란 최소단위를 갖고 고정된 크기의 데이터를 읽고 쓰는 장치구동기를 말한다. 2)character device driver란 고정된 크기가 사용자의 자유에 따라 임의 크기의 데이터를 읽고 쓸 수 있는 장치구동기를 말한다.
퀴즈
퀴즈1) access time 중 탐색시간(seek time)이란 무엇을 의미하는가.
퀴즈2) 최단탐색시간 우선스케줄링은 현재 헤드의 위치로부터 가장 가까운 실린더에 놓인 데이터를 먼저 처리하는 방법이다. 이 스케줄링의 단점은 무엇인가.
퀴즈3) Look algorithm의 특성을 설명하시오.
퀴즈4) I/O시스템은 커널을 통해 명령받게 된다. 명령이 주어진 이후 필요한 각각의 장치와 기능을 설명하시오.
퀴즈5) 장치구동기(Device driver) 중 block device driver란 어떤 특성을 갖고 있나.
정답1) linked list allocation는 순차접근을 할 경우 연결된 포인터만 쫓아가면 되므로 효율적인 방법이 된다. 그러나 임의 접근을 시도할 경우 내가 찾고자 하는 데이터가 리스 트로 연결된 블록 가운데 마지막에 있다 하더라도 처음 블록부터 찾아야 하므로 비효율적인 방법이다.
정답2) read/write 헤드를 데이터가 저장되어 있는 트랙위치로 이동시키는데 소요되는 시간을 말한다.
정답3) 현재 헤드가 놓인 위치로부터 최단거리에 놓인 데이터들이 계속해서 요구되어지는 경우가 발생하면 무한정 기다림을 갖는 데이터가 생기게 된다.
정답4) 주어진 데이더 요구값에 가장 작은 번호부터 가장 큰 번호까지 처리하는 방법이다. 정답5) 하나의 명령이 주어지면 장치구동기(Device driver)를 통해 추가 명령이 실행될 주변 장치를 제어, 관리하게 되고 이어 장치제어기(Device controller)를 통해 실행 하드웨어가 작동된다.
정답4) block device driver는 최소단위를 갖고 고정된 크기의 데이터를 읽고 쓰는 장치구동기를 말하는 것으로 디스크와 CD-ROM등이 이에 속한다.
안녕하세요? 허니입니다. 운영체제에서 디스크 공간 할당(Disk Space Allocation)의 알고리즘과 효과적 알고리즘의 판단 기준에 대해 포스팅 하도록 하겠습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
disk space allocation의 알고리즘
contiguous
linked list allocation
index
indexed allocation
효과적 알고리즘의 판단 기준
순차 접근(sequential access)
임의 접근(random access)
디스크 공간 할당(Disk space allocation)
파일 시스템을 학습하면서 이 시점에서 생각해야 할 것은 연속된 바이트의 연속으로 구성된 파일을 디스크 블록에 어떤 형식으로 저장시킬 것인가 하는 점이다. 이것을 바꿔 말하면 사용자가 하나의 파일을 불러올 때 디스크 이곳저곳에 블록단위로 흩어져있는 파일을 보다 신속하게 찾아내고 신속하게 저장하기 위해서 그 동안 어떤 방법들이 사용되었는지를 알아보는 것이다. 그 동안 디스크 공간에 파일을 할당하는데는 다음과 같은 방법들이 있다.
연속적 할당 (contiguous allocation) 하나의 파일을 디스크에 할당할 때 인접한 섹터들을 할당하여 최소의 시간으로 데이터를 읽어들일 수 있도록 하는 것이다. 이 방법이 활용되기 위해선 파일의 크기를 할당할 때에 알고 있어야 한다. 만약 현재 사용할 파일이 1Mbyte라면 디스크는 1Mbyte를 연속된 섹터들을 할당해 놓는 것이다.
그림 61 Contiguous Allocation
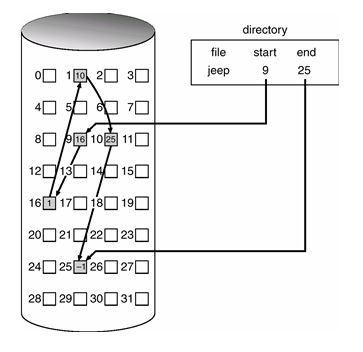
linked list allocation 연속할당 방법의 단점은 하나의 파일을 인접한 섹터을 할당하여 채움으로서 그만큼 디스크가 효율적으로 사용되지 못하다는 것 이었다. 디스크 곳곳에 사용되지 않은 블록이 있다 하더라도 그 블록이 현재 저장해야하는 파일의 크기보다 작다면 사용될 수 없기 때문이다. 디스크 공간을 보다 효율적으로 운영하는 방법을 고심하던 시스템 설계자들은 블록을 리스트로 연결해 블록이 디스크상에 떨어져 있어도 하나의 파일을 할당할 수 있는 linked list allocation을 구상하기 시작했다. 여러 개의 디스크블록이 필요한 파일을 저장할 때 인접한 섹터가 아니더라도 저장이 가능한데 이 이유는 파일의 가장 앞부분을 저장한 블록이 그 다음 저장 블록이 어느 곳에 위치해 있는지 포인터를 통해 알려주기 때문이다. 만약 10개의 떨어진 블록이 사용되었다면 각자 다음 순서의 블록이 어디 위치해있는지에 관한 정보를 갖고 있는 것이다. 시스템 사용 중 데이터를 삽입하거나 삭제하는 등의 행동은 바로 파일 크기의 변화를 가져온다. 이렇게 파일의 크기가 동적일 때 즉, 디스크 블록이 더 필요한 경우가 발생했을 때 필요한 블록이 디스크상에 어느 위치에 있다하더라도 포인터를 통해 연결이 가능하므로 편리하다.
그림 62 Linked List Allocation
보통의 경우 블록하나씩 포인터로 연결되는 경우는 적고 여유가 있는 인접한 블록에 파일을 저장한 다음 인접블록이 없을 경우 또 다른 블록에 포인터가 연결되게 된다.
index 앞서 우리는 파일의 논리적 블럭이 디스크의 물리적 블록으로 변화되는 원리를 공부해 보았다. 그렇다면 논리적 블록과 물리적 블록간에 연결사항을 알고 있다면 보다 쉽게 디스크에 저장되어 있는 파일을 찾을 수 있지 않을까. 바로 이런 생각에서 만들어진 것이 인덱스이다. 책에서 어느 한가지 내용을 찾고자 할 때 우리는 맨 첫 장부터 페이지를 한 장 한 장 넘기며 찾지 않는다. 보다 간편하게 원하는 내용을 찾기 위해 책 앞부분에 인덱스를 참고하게 되는 것이다. 그와 같이 내가 현재 필요로 하는 파일이 디스크 내부에 어떤 실린더 주소와 블록 주소를 갖고 있는지에 대해 도표를 만들게 되는 것이다. 이 방법은 linked list allocation처럼 파일 크기가 동적일 때 편리하다. 어떠한 내용 삽입으로 인해 기존 파일보다 크기가 커져 별도의 디스크블록에 삽입된 내용이 저장되었다면 인덱스 항목을 통해 늘어난 파일이 디스크 어느 블록에 저장되어 있는지 표시하면 되기 때문에 파일 크기 변화에 대한 대처가 발빠르게 진행된다.
논리적 블록
물리적 블록
0
(24,37)
1
(18,29)
2
(34,52)
3
(21,7)
4
(8,3)
그러나 이러한 인덱스를 통한 할당방법 역시 완벽한 것은 아니었다. 어떠한 문제점을 갖고 있는지 한번 살펴보자. 디스크블록포인터가 32bit, 디스크의 I/O 블록은 4Kbyte를 갖게 된다고 한다면 이러한 32bit(4byte)의 디스크 블럭 포인터는 실린더번호와 섹터 번호를 표기하게 된다. 또한 하나의 인덱스 블록에는 1024개의 포인터 항목들이 존재하고 하나의 인덱스 블록이 가르킬 수 있는 파일의 크기는 4Mbyte(1024포인터X4kbyte)인 것이다. 만약 파일의 크기가 8Mbyte라면 두 개의 인덱스 블록이 필요하게 되고 16Mbyte이면 4개의 인덱스 블록이 필요하게 된다. 파일의 크기가 1Gbyte라면 인덱스블록은 250개나 필요하다. 계속해서 파일의 크기가 커질수록 인덱스 블록의 갯수 또한 늘어나게 되는 것이다.
인덱스 블록이 증가한다는 것은 어떤 문제를 발생시킬까? 임의에 블록을 읽기 위해 인덱스 블록을 검색하기 위해서는 맨 처음 인덱스 블록부터 차례대로 접근해야 한다. 불행하게도 내가 찾는 인덱스 항목이 인덱스블록 가장 끝에 존재한다면....바로 파일이 클수록 인덱스블록의 수는 늘어나고 인덱스 항목을 검사하는데는 그 만큼 긴 시간이 걸리게 되는 것은 너무도 당연한 노릇이다. 그렇기에 멀티레벨페이지테이블과 같이 인덱스 블록을 하나 더 추가하는 것을 고려하게 되었다. 그러나 인덱스 블록이 하나 더 추가되어 사용되었지만 이 또한 100% 만족을 가져오지는 못했다. 인덱스 블록이 하나일 경우 헤드가 2번의 접근을 시도함으로서 디스크에 저장되어 있는 파일을 불러올 수 있었다. 인덱스블록을 한번 읽고 데이터 블록을 찾아가 저장된 파일을 읽어오면 되었지만 2레벨 인덱스 블록의 경우 3번의 접근을 시도해야 했다.
그림 63 2레벨 인텍스 블록
또한 파일의 크기가 4Mbyte 이하일 경우를 한번 생각해 보자. 이럴 경우 인덱스 블록 하나로도 4Mbyte 파일의 물리적 블록과 디스크에 논리적 블록간에 표시가 가능하므로 2레벨 인덱스블록은 낭비를 가져오게 된다. 결론적으로 파일이 클 경우 2레벨 인덱스 블록이 보다 효과적이지만 파일이 작을 경우 하나의 인덱스 블록이 효과적인 것이다. 그렇다면 이 두 가지의 방법을 적절히 섞어 사용하게 되면 어떨까.
Hybrid allocation 이 방법은 바로 블록 전체를 인덱스로 채우는 것이 아니라 파일의 크기가 4Mbyte 이하일 경우와 그 이상일 경우 또한 매우 클 경우 등 3가지의 경우를 염두에 두고 다이렉트 블록 포인터를 연결하는 것이다. 다음 그림과 같이 1레벨은 하나의 인덱스 블록을 통해 직접 데이터 블록에 연결시키고 2레벨은 두 개의 인덱스 블록에 또한 3레벨은 3개의 인덱스 블록에 접근을 시도함으로서 데이터블록을 찾아가는 것이다.
알고리즘이 가장 효율적으로 판단하는 기준
어떤 알고리즘이 가장 효율적이냐를 판단하기 위해선 어떤 하나의 잣대가 필요한 것이다. 다음의 순차접근(sequential access)과 임의 접근(random access)의 두 가지 기준의 내용을 알아보고 앞서 말한 4가지의 디스크 공간 할당 방법의 장단점을 구분해 보자.
순차접근(sequential access) 순차접근은 데이터가 저장되어 있는 파일을 앞에서 뒤로 순차적으로 접근하는 방식을 말한다. 자기테입의 경우 테이터에 접근하기 위해 테입을 앞뒤로 감아야 하기 때문에 테이터가 저장되어 있는 위치에 따라 순차적으로 접근하게 되는 것이다.
임의접근(random access) 임의접근은 데이터가 저장되어 있는 위치에 상관없이 접근하는 방식을 말한다. 자기디스크에 데이터가 저장되어 있을 경우 앞 뒤 구분없이 임의의 데이터에 접근하게 되는 것이다.
자, 그럼 이제부터 앞서 공부한 디스크 할당 방식을 비교해보자.
contiguous의 디스크공간 할당은 데이터의 첫 위치만 알면 헤드가 연속적으로 데이터를 읽게 되므로 순차접근을 기준으로 보았을 때 좋은 방법이다. 임의 접근을 기준으로 보았을 때도 연속적 할당은 별다른 문제가 존재하지 않는다.
linked list allocation의 경우는 순차접근을 할 경우 연결된 포인터만 쫓아가면 되므로 효율적인 방법이 된다. 그러나 임의 접근을 시도할 경우 내가 찾고자 하는 데이터가 리스트로 연결된 블록 가운데 마지막에 있다 하더라도 처음 블록부터 찾아야 하므로 비효율적인 방법이다.
index는 물리적 블록에 파일들이 흩어져 있으므로 순차접근과 임의접근 두 가지 모두 비슷한 성능을 보인다.
요점정리
disk space allocation 1) 연속적 할당 (contiguous allocation) 하나의 파일을 디스크에 할당할 때 인접한 섹터들을 할당하여 최소의 시간으로 데이터를 읽어들일 수 있도록 하는 것이다. 2) linked list allocation 여러개의 디스크블록이 필요한 경우 파일을 저장할 때 인접한 섹터가 아니더라도 포인터를 통해 연결된 파일이 저장된 블록을 알려주게 되는 할당방법이다. 3) index 파일과 디스크간에 로지컬블럭과 피지컬블록의 연결사항을 도표로 만들어 표시하는 할당방법이다. 4) Hybrid allocation 이 방법은 바로 블록 전체를 인덱스로 채우는 것이 아니라 파일의 크기가 4Mbyte 이하일 경우와 그 이상일 경우 또한 매우 클 경우등 3가지의 레벨를 염두에 둔 것으로 1레벨은 하나의 인덱스 블록을 통해 직접 데이터 블록에 연결시키고 2레벨은 두 개의 인덱스 블록에 또한 3레벨은 3개의 인덱스 블록에 접근을 시도함으로서 데이터블록을 찾아가는 것이다.
순차접근(sequential access)과 임의 접근(random access) 1) 순차접근(sequential access) 순차접근은 데이터가 저장되어 있는 파일을 앞에서 뒤로 순차적으로 접근하는 방식을 말한다. 2) 임의 접근(random access) 임의접근은 데이터가 저장되어 있는 위치에 상관없이 접근하는 방식을 말한다.
퀴즈
퀴즈1) 디스크공간 할당 방법 중 연속적 할당 (contiguous allocation)의 방법과 장점을 설명하시오.
퀴즈2) linked list allocation은 파일 크기가 동적일 때 유용하다. 그 이유를 설명해 보시오.
퀴즈3) 인덱스 블록이 증가한다는 것은 어떤 문제를 발생시킬까.
퀴즈4) Hybrid allocation은 인덱스 방법을 보다 효율적으로 설계한 것이다. 그 특성을 설명해 보시오.
퀴즈5) linked list allocation를 순차접근과 임의접근을 기준으로 효율성을 비교해 보시오.
정답1) 하나의 파일을 디스크에 할당할 때 인접한 섹터들을 할당하는 방법으로 최소의 시간으로 데이터를 읽어들일 수 있는 장점을 갖고 있다.
정답2) 시스템 사용 중 데이터를 삽입하거나 삭제하는 등의 행동은 바로 파일 크기의 변화를 가져온다. 이렇게 파일의 크기가 동적일 때 즉, 디스크 블록이 더 필요한 경우가 발생했을 때 필요한 블록이 디스크상에 어느 위치에 있다하더라도 포인터를 통해 연결이 가능하므로 편리하다.
정답3) 임의에 블록을 읽기 위해 인덱스 블록을 검색하기 위해서는 맨 처음 인덱스 블록부터 차례대로 접근해야 하기 때문에 인덱스블록이 증가한다는 것은 인덱스 항목을 검사하는데 그 만큼 긴 시간이 걸리는 문제가 발생된다.
정답4) 이 방법은 바로 블록 전체를 인덱스로 채우는 것이 아니라 파일의 크기가 4Mbyte 이하일 경우와 그 이상일 경우 또한 매우 클 경우등 3가지의 레벨을 염두에 둔 것으로 1레벨은 하나의 인덱스 블록을 통해 직접 데이터 블록에 연결시키고 2레벨은 두 개의 인덱스 블록에 또한 3레벨은 3개의 인덱스 블록에 접근을 시도함으로서 데이터블록을 찾아가는 것이다.
안녕하세요? 허니입니다. 파일 시스템에 대해 어느정도 익숙하신 분들이라면 파일시스템의 내부 구조가 궁금하실 거라 생각합니다. 이번에는 파일시스템을 더 자세하게 즉, 내부 구조에 대해 포스팅을 하겠습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하며 언제든지 질문은 환영입니다.
오늘의 주제
파일시스템의 내부구조
boot block
file system descriptor
file descriptor
data block
디스크의 구조
파일의 read/write 경로
read/write 하기 위한 정보
파일 시스템의 내부구조
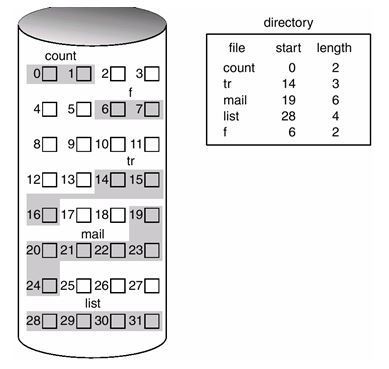
파일 시스템은 다음과 같은 여러개의 물리적인 분할 영역(partition)으로 구성되어있다.각각의 partition을 보다 상세히 살펴보자.
부트블록(boot block) boot라는 것은 컴퓨터를 켤 때 컴퓨터가 동작할 수 있도록 하는 준비 작업을 말한다. 바로 컴퓨터가 부팅 될 때 시스템에 OS를 설치하기 위해서 필요한 정보들이 저장되어 있는 디스크 영역이 부트블록이다. 다시 말해 OS가 디스크를 포함한 시스템을 제어하기 위해 필요로 하게 되는 정보들이 저장되어 있는 블록인 것이다.
파일시스템 설명자(file system descriptor) 파일 시스템 설명자에는 파일의 크기, 파일의 개수, 디스크의 특성, 디스크블록이 먼지 등에 의해 손상했는 지의 여부 등이 판단되는 bad 블록 등의 내용이 담겨져 있다.
파일 설명자(file descriptors) 파일은 컴퓨터를 껐다 켜도 남아있게 마련이다. 그것은 파일이 이미 디스크에 블록단위로 저장되어 있기 때문이다. 그렇기 때문에 파일이 어떤 블록에 저장되어 있는지를 알려주는 정보가 있어야 하는데 그러한 정보는 바로 file descriptor에 저장되어 있는 것이다. 앞서 설명한 Meta data도 file descriptor에 기록되어 있다.
데이터블록(data block) 데이터 블럭은 찾고자하는 실제 데이터들이 저장되어 있는 블록인 것이다. 데이타들을 찾기 위한 가장 밀접한 정보들은 파일설명자에 저장되어 있기 때문에 데이터 블록과 거리상으로 밀접해야 한다. 그러나 디스크의 용량이 자꾸 커져감에 따라 하나하나의 파일설명자블록과 데이터 블록이 멀어져가게 되었다. 그렇기에 최근에는 파일설명자의 정보를 디스크를 구성하고 있는 실린더 곳곳에 분산시켜 놓게 되었다.
디스크의 구조
디스크는 트랙이라고 불리는 동심원에 자료를 저장하는데 이 동심원은 자기적으로 만들어진 것이기 때문에 눈으로 볼 수는 없다. 또한 하나의 트랙은 여러 개의 섹터로 나뉜다. 이러한 트랙들의 수직적 집합을 바로 실린더라고 한다. 데이터들은 트랙에 비트 형태로 저장되는데 디스크의 기억용량은 한 면 당 트랙의 수, 비트의 밀도, 기록 가능한 면의 수 등에 의해 결정된다. 한 면 당 트랙의 수는 디스크의 물리적 크기, 자료를 기록하는 기술 등에 따라 다르다.
그림 58 디스크의 구조
자료를 읽고 쓰기 위해서는 읽기/쓰기 헤드가 원하는 자료가 위치하고 있는 트랙 위에 위치해야 한다. 읽기/쓰기 arm이 원하는 자료의 위치를 찾아내면 디스크를 읽기/쓰기 헤드밑에서 회전하게 함으로써 필요한 자료에 접근할 수 있다. 보통 여러 개의 flat이 있을 경우에는 여러 개의 접근 arm을 사용하게 되는 것이다.
그림 59 하드 디스크의 Arm
파일을 read/write 하는데 어떤 경로로 이뤄질까?
파일을 read/write 하기 위해서는 open이라는 과정을 거치게 된다. 컴퓨터 시스템에게 파일을 사용하겠다는 통보가 이뤄지는 단계로 파일이름을 확인하고 그 파일에 접근가능한지를 판단하고 파일설명자를 할당하게 된다. read/write를 하게 될 파일이 실제 존재한다는 것은 디렉토리를 살펴봄으로 확인이 가능하다. 파일의 존재와 접근여부를 확인한 후 리턴하여 실제 파일을 open 하게 되는 것이다.
read/write 어떤 정보들을 통해 실행될까.
read/write의 실행 정보를 살펴보기에 앞서 read/write 명령어가 어떤 수행을 하는지 잠깐 살펴보자. read란 명령이 떨어지면 버퍼캐쉬에 있는 내용을 사용자 버퍼로 읽어오는 동작이 이뤄지고 write라는 명령은 버퍼에 내용을 버퍼캐쉬에 쓰는 동작을 한다. 실제로 어떤 한 파일에 대한 read를 실행하게 되면 다음과 같은 정보들이 참조되어 처리되게 된다.
- read (파일설명자, 버퍼, 길이, 내부주소)
각각의 의미를 알아보면 다음과 같다.
정보
의미
파일 디스크립터
파일이 저장되어 있는 디스크블록에 관한 정보 제공
버퍼
디스크로부터 읽어 들어올 주소
길이
읽으려는 바이트 수
내부주소
파일의 현재위치, 파일 포인터가 내부주소를 가르킴
예를 들어 read( fd, buf1, 100, 35)이면 100바이트를 buf1에 35로부터 읽어오기를 의미한다. 여기에서 read의 역할은 파일을 읽고 파일포인터를 옮기는 것이다. 이와 같이 write( fd, buf4, 300, 20) 이라고 명령되면 buf4의 20으로부터 300바이트 쓰기가 실행되는 것이다.
보다 상세히....프로세스와 연결시켜....
1) read가 명령되면 먼저 파일 설명자를 체크하게 된다. 파일 설명자를 체크하고 파일의 현재위치를 알아내게 되면 먼저 그 파일이 버퍼 캐쉬에 저장되어 있는지를 확인한다.
2) 버퍼캐쉬 확인 만약 버퍼캐쉬에 찾고자하는 파일이 있으면 그 내용을 그대로 read하면 된다. 그러나 버퍼캐쉬에 찾고자하는 파일이 없을 경우 다음과 같은 일이 진행된다.
3)파일 설명자를 통해 알아낸 파일의 현재 위치로부터 주어진 길이까지 해당되는 물리적 디스크블록을 찾는다. 그러나 여기서 한가지 문제에 부딪히게 되는 것이다. 바로 파일은 연속적으로 존재하지만 이 파일이 디스크상으로 저장될 때는 블록단위로 쪼개져 이곳 저곳에 흩어져 저장되어 있는 것이다. 그렇기에 논리적인 파일 offset을 물리적인 디스크 블록으로 매핑해야 하는 과정이 필요하다.
4) 디스크에 블록으로 저장된 파일의 위치는 찾는 작업이 끝나면 디스크 I/O을 통해 장치구동기(Device driver)를 호출하게 된다.
5) 장치구동기(Device driver)는 커널로부터 read에 관한 요구사항을 받아 디스크 컨트롤러에게 다음과 같은 명령을 한다. (read/write,실린더 번호, 블록번호) 몇 번 실린더에 몇 번 블록을 리드 혹은 라이트해라.
6) 디스크컨트롤러에게 명령이 전해졌다고 해서 바로 작업이 수행되는 것은 아니다. 서론에서 공부한 프로세스라이프사이클에 따라 sleep 상태로 들어가게 되는 것이다. sleep 상태로 들어가는 이유는 호출한 장치구동기(Device driver)가 서비스를 제공하기 위한 해당 조건이 만족될 때를 기다리기 위해서이다.
이러한 명령을 받은 디스크 컨트롤러는 다음과 같은 과정을 거친다. 1.해당파일을 찾고 2.DMA (direct memory access) 메모리에 접근해 입력/출력을 버퍼캐쉬를 통해 처리하고 3.인터럽터를 건다. 인터럽트를 수행하는 프로세스는 해당 서비스 루틴을 wake up 시키고 버퍼에 저장되어 있는 내용을 카피해 리턴하게 되는 것이다. read/write 한가지를 수행하기 위해서도 컴퓨터 시스템 내부적으로는 이와 같이 복잡한 과정들을 거치게 되는 것이다.
그림 60 Read/Write의 수행과정
잠깐, 상식!
장치구동기(Device driver) 란... 프린터, 모니터, 디스크 등과 같은 주변장치들을 제어하고 관리하는 방법을 OS에게 알려주는 프로그램. OS에서는 시스템에 설치되어 있는 주변장치를 제어, 관리하기 위하여 Device driver에서 제공되는 기능을 이용한다.
요점정리
파일 시스템의 내부구조 1) 부트블록(boot block) 2) 파일시스템 설명자(file system descriptor) 3) 파일 설명자(file descriptors) 4) 데이터블록(data block)
디스크의 구조 디스크는 트랙이라고 불리는 동심원에 자료를 저장하고 하나의 트랙은 여러 개의 섹터로 나뉜다. 이러한 트랙들의 집합을 바로 실린더라고 한다. 이러한 실린더의 집합을 디스크라고 한다.
read/write의 실행정보: read (파일설명자, 버퍼, 길이, 내부주소)
퀴즈
퀴즈1) 파일 시스템의 내부구조중 파일 설명자(file descriptors)의 역할은 무엇인가?
퀴즈2) 파일을 read/write 하기 위해서는 open이라는 과정을 거치게 된다. open을 통해 어떤 일들이 수행되나?
퀴즈3) read( fd, buf1, 100, 35)이라는 명령문이 의미하는 것은 무엇인가?
퀴즈4) read가 명령되면 먼저 파일 설명자를 체크하고 명령을 수행하기 앞서 버퍼캐쉬 확인하게 된다. 그 이유는 무엇인가?
퀴즈5) 디스크컨트롤러에게 명령이 전해졌다고 해서 바로 작업이 수행되는 것은 아니라 우선 sleep 상태로 들어가게 된다. 그 이유는 무엇인가?
정답1) 파일설명자는 파일이 어떤 블록에 저장되어 있는가 하는 정보를 알려주는 역할을 한다.
정답2) open은 컴퓨터 시스템에게 파일을 사용하겠다는 통보가 이뤄지는 단계로 파일이름을 확인하고 그 파일에 접근가능한지를 판단하고 파일설명자를 할당하게 된다.
정답3) 100바이트를 buf1의 35로부터 읽어오기를 의미한다.
정답4) 만약 버퍼캐쉬에 찾고자하는 파일이 있으면 그 내용을 그대로 read하면 되기 때문에 명령문 수행에 앞서 버퍼캐쉬를 확인하는 것이다.
정답5) sieep 상태로 들어가는 이유는 호출한 장치구동기(Device driver)가 서비스를 제공하기 위한 해당 조건이 만족될 때를 기다리기 위해서이다.




























































































 Interrupt controller
Interrupt controller