MLflow로 작업 생산성 높이고 머신 러닝 프로젝트 관리하기
MLflow는 개발자들이 기계 학습 프로젝트를 관리하고 추적할 수 있도록 도와주는 오픈 소스 플랫폼입니다. MLflow는 일련의 구성 요소로 구성되어 있으며, 이를 통해 프로젝트 수명주기의 각 단계에서 다양한 작업을 수행할 수 있습니다. 이러한 구성 요소는 "Tracking", "Projects", "Models", "Registry"로 구분됩니다.
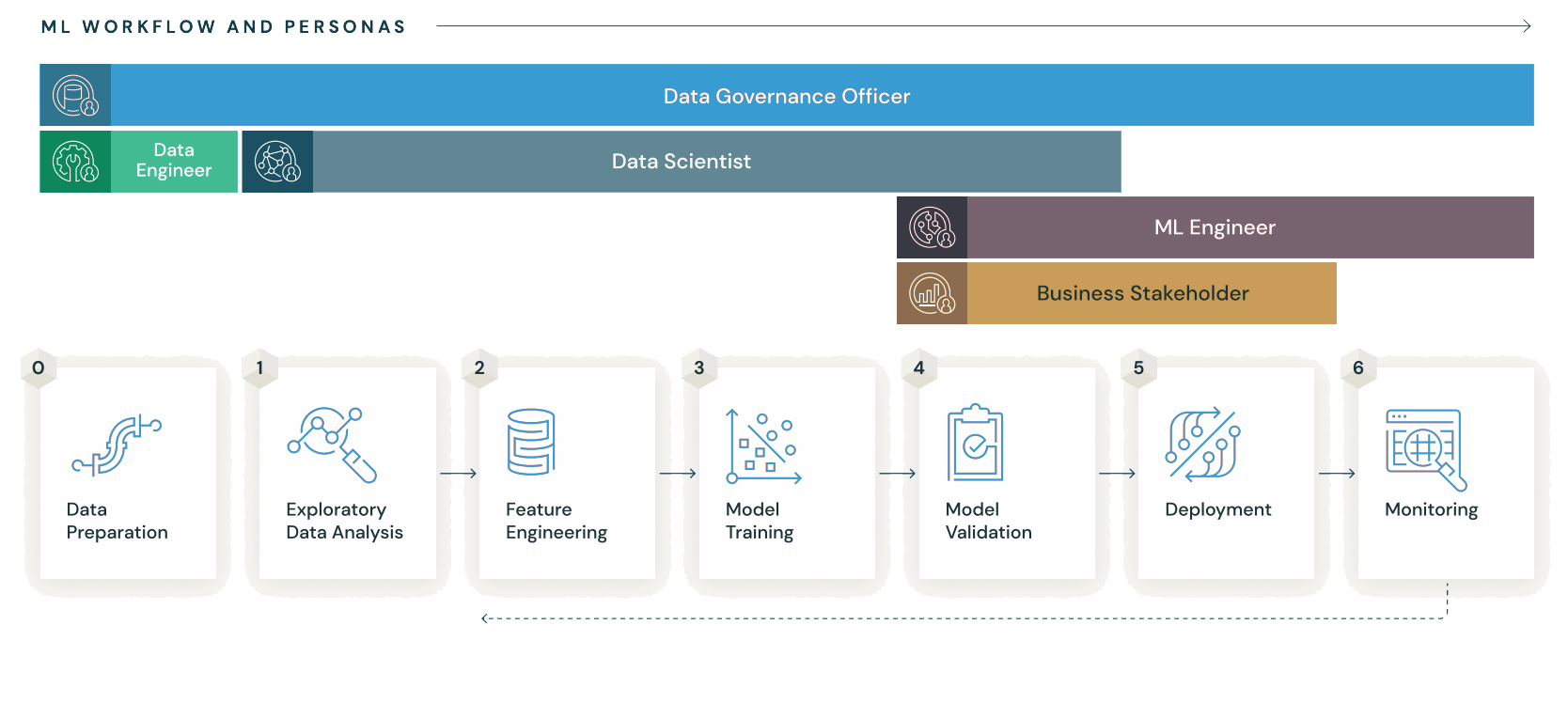
- "Tracking"은 모델을 훈련하고 실험을 기록하는 데 사용됩니다. 모델 훈련 코드에 MLflow 라이브러리를 추가하여 훈련 단계에서 로그를 기록할 수 있습니다. 이렇게 기록된 정보는 실행된 매개변수, 메트릭, 결과 모델 등을 포함합니다. 이렇게 기록된 정보는 웹 기반 대시보드를 통해 확인할 수 있으며, 실험 결과를 비교하고 모델 성능을 모니터링할 수 있습니다.
- "Projects"는 MLflow에서 모델 훈련 코드와 관련 파일을 구성하고 패키징하는 데 사용됩니다. 이러한 프로젝트는 특정 코드 실행 환경이나 종속성을 통일하여 배포 및 재현성을 쉽게 유지할 수 있도록 도와줍니다. 프로젝트는 Git 저장소에서 추적되며, 다양한 플랫폼에서 실행할 수 있는 Docker 컨테이너나 Conda 환경으로 패키징될 수 있습니다.
- "Models"는 모델 아티팩트를 저장하고 추적하기 위한 저장소 역할을 합니다. MLflow는 다양한 형식의 모델 아티팩트를 관리할 수 있으며, 훈련된 모델을 추적하고 검색할 수 있는 기능을 제공합니다. 또한, MLflow는 모델 버전 관리를 지원하여 모델을 관리하고 추적할 수 있게 합니다.
- "Registry"는 모델 버전 관리 및 추적에 사용되는 센트럴 저장소 역할을 합니다. 이를 통해 팀 내에서 모델을 공유하고, 모델에 대한 메타데이터 및 태깅을 관리할 수 있습니다. MLflow Registry는 모델의 라이프사이클을 관리하며, 이를 통해 모델을 배포하고 추론 환경에서 사용할 수 있습니다.
MLflow는 다양한 언어 및 프레임워크에서 사용할 수 있도록 설계되어 있습니다. 또한, 클라우드 기반 환경과의 통합도 지원하며, 여러 사람이 동시에 작업할 수 있는 다중 사용자 지원도 제공합니다. 이러한 기능은 프로젝트를 효율적으로 관리하고 협업을 강화하는 데 도움을 줍니다. MLflow는 머신러닝 프로젝트를 보다 효율적으로 관리하고 추적할 수 있도록 도와줍니다. 이를 통해 개발자들은 모델을 개발하고, 실험하고, 배포하는 과정에서 생산성을 향상시킬 수 있습니다. MLflow는 커뮤니티에서 활발히 개발되고 있으며, 관련 문서와 예제를 통해 더 많은 정보와 지원을 얻을 수 있습니다.
MLflow - A platform for the machine learning lifecycle
An open source platform for the end-to-end machine learning lifecycle
mlflow.org
MLflow 사용 방법은?
- MLflow 설치: 먼저, MLflow를 설치해야 합니다. 아래 명령어를 사용하여 설치할 수 있습니다.
pip install mlflow- MLflow 서버 실행: MLflow 서버를 실행하기 위해서는 다음과 같은 명령어를 사용합니다.
mlflow server --default-artifact-root=<artifact_store_directory> --host <host_name> --port <port_number>여기서 <artifact_store_directory>은 저장소 경로이며, <host_name>과 <port_number>는 서버 호스트 이름과 포트 번호입니다.
- MLflow 코드 추가: MLflow 코드를 작성하기 위해서는 프로젝트 파일을 생성하고, 코드 내에 다음과 같은 라이브러리를 추가해야 합니다.
import mlflow이후, MLflow의 기능 중에서 원하는 기능(Tracking, Projects, Models, Registry)을 사용하여 코드를 작성합니다. 예를 들면, mlflow.log_param() 함수를 사용하여 매개변수를 로깅할 수 있습니다. 이렇게 로깅된 정보는 MLflow 서버에서 확인할 수 있습니다.
- MLflow 실행: 마지막으로, MLflow 코드를 실행해야 합니다. 아래 명령어를 사용하여 코드를 실행합니다.
mlflow run <project_directory> -P <param_name>=<param_value> -P <param_name>=<param_value> ...여기서 <project_directory>는 프로젝트 경로이며, -P 옵션을 사용하여 매개변수를 설정할 수 있습니다. 이렇게 하면 MLflow를 사용하여 모델 훈련 코드를 작성하고 관리할 수 있습니다. 추가적으로, MLflow UI를 사용하여 모델 결과를 시각화하고 비교할 수 있습니다. MLflow를 사용하면 머신 러닝 프로젝트를 보다 효율적으로 관리할 수 있으며, 다른 개발자와 협업하는 과정에서도 유용하게 사용될 수 있습니다.
What is MLflow? — MLflow 2.4.1 documentation
What is MLflow? MLflow is a versatile, expandable, open-source platform for managing workflows and artifacts across the machine learning lifecycle. It has built-in integrations with many popular ML libraries, but can be used with any library, algorithm, or
mlflow.org
MLflow를 사용한 모델 훈련 성능 향상에 대한 팁이 있나요?
MLflow는 모델 훈련 프로세스를 관리하는 데 도움이 되는 도구입니다. 그러나 모델 훈련 성능 향상에 대해서는 MLflow 자체적으로 직접적인 영향을 주지는 않습니다. 따라서, MLflow를 사용하여 모델 성능을 향상시키기 위해서는 다음과 같은 팁들이 유용할 수 있습니다.
- 데이터 전처리: 모델 성능에 큰 영향을 주는 것 중 하나는 데이터 전처리입니다. 적절한 데이터 전처리 기술을 사용하여 데이터를 정규화하고, 이상치를 제거하고, 누락된 데이터를 보완하는 등의 작업을 수행해야 합니다.
- 하이퍼파라미터 튜닝: 하이퍼파라미터는 머신 러닝 모델에서 학습하는 동안 조정할 수 있는 매개변수입니다. 모델의 하이퍼파라미터를 적절하게 조정하여 모델의 일반화 성능을 향상시킬 수 있습니다. Grid Search, Random Search, Bayesian Optimization 등의 방법을 사용하여 하이퍼파라미터의 최적값을 찾을 수 있습니다.
- 앙상블 모델 적용: 앙상블 방법은 다수의 모델을 조합하여 단일 모델의 성능을 향상시키는 기법입니다. 다양한 앙상블 방법 중에서는 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 등의 방법이 있으며, 모델의 일반화 성능을 향상시킬 수 있습니다.
- 더 큰 모델 사용: 더 큰 모델을 사용하여 모델 성능을 향상시킬 수 있습니다. 딥러닝 모델일 경우, 더 많은 층과 더 많은 뉴런을 포함하는 모델을 사용할 수 있습니다. 하지만, 더 큰 모델을 사용할 경우, 모델의 복잡도와 연산량이 증가하므로, 적절한 컴퓨팅 자원이 필요합니다.
이러한 팁들을 참고하여 MLflow를 사용하여 모델 성능을 향상시킬 수 있습니다. MLflow를 사용함으로써 모델 훈련 과정을 더욱 체계적으로 관리하고, 분석하여 개발자들은 모델 훈련 과정에서 더욱 빠르게 경험을 쌓을 수 있습니다.
'Artificial Intelligence(인공지능)' 카테고리의 다른 글
| AIoT: 애플의 새로운 AI 기술의 혁신 HomePod (0) | 2023.07.05 |
|---|---|
| AIoT: Google Nest으로 스마트 홈을 (0) | 2023.07.04 |
| LLM(Large Language Models): AI의 대화 능력, LaMDA가 만들어낸 혁명 (0) | 2023.07.03 |
| LLM(Large Language Models): 언어 생성을 위한 AI 혁신 GPT (0) | 2023.07.02 |
| MLOps: 데이터 버전 관리를 위한 혁신, DVC(Data Version Control) (0) | 2023.07.01 |