LLM(Large Language Models): GPT: 언어 생성을 위한 AI 혁신
GPT(Generative Pre-trained Transformer)는 딥러닝 모델 중 하나로, OpenAI에서 개발된 자연어 처리 모델입니다. GPT는 대규모의 텍스트 데이터를 이용하여 사전 훈련된 모델입니다. 이 모델은 언어 이해, 생성 및 기계 번역과 같은 다양한 자연어 처리 작업을 수행할 수 있습니다.
Generative pre-trained transformer - Wikipedia
From Wikipedia, the free encyclopedia Type of large language model Generative pre-trained transformers (GPT) are a type of large language model (LLM)[1][2][3] and a prominent framework for generative artificial intelligence.[4][5] The first GPT was introdu
en.wikipedia.org
GPT는 Transformer 아키텍처를 기반으로 하고 있습니다. Transformer는 기존의 순차적인 RNN(Recurrent Neural Network)이나 CNN(Convolutional Neural Network) 대신에 어텐션 메커니즘을 사용하여 번역 및 자연어 처리 작업에 탁월한 성능을 보입니다. 이러한 Transformer 구조를 사용하여 GPT 모델은 문맥을 이해하고 자연스러운 텍스트를 생성할 수 있습니다. GPT의 핵심 아이디어는 사전 훈련과 세부 조정 두 단계로 나누어진다는 점입니다.
- 사전 훈련은 대량의 텍스트 데이터에 대해 비지도 학습을 통해 수행됩니다. 이 과정에서 GPT는 문맥을 이해하고 다른 단어들과의 상관 관계를 학습합니다. 이렇게 사전 훈련된 GPT 모델은 다양한 자연어 처리 작업에 활용할 수 있습니다.
- 세부 조정 단계에서는 사전 훈련된 GPT 모델을 특정 작업에 맞게 세부 조정하여 추가 학습을 수행합니다. 이 과정에서는 작업에 필요한 데이터를 사용하여 GPT 모델을 미세 조정하여, 해당 작업에 최적화된 모델을 만들 수 있습니다. 세부 조정 과정은 사전 훈련 단계에서 학습된 일반적인 텍스트 이해 능력을 특정 작업에 맞게 조정하여 작업 성능을 극대화하는 역할을 합니다.
GPT는 다양한 응용 분야에서 활용될 수 있습니다. 예를 들어, 기계 번역에서는 GPT를 사용하여 입력 문장을 다른 언어로 번역하는 작업을 수행할 수 있습니다. 자연어 이해에서는 GPT를 사용하여 주어진 문장의 의미나 의도를 파악할 수 있습니다. 또한, 자연어 생성에서는 GPT를 사용하여 자연스러운 텍스트를 생성할 수 있습니다. GPT는 현재까지도 계속해서 개선되고 있으며, 딥러닝과 자연어 처리 분야에서 많은 연구와 관심을 받고 있습니다. GPT의 발전은 앞으로 자연어 이해와 생성 작업을 보다 효율적으로 수행할 수 있는 가능성을 열어줄 것입니다. 하지만, GPT는 모델의 한계와 제한사항을 가지고 있습니다. 예를 들어, GPT는 오류가 발생할 수 있는 경향이 있으며, 입력된 정보에 바탕을 둔 합리적인 결론을 내릴 수 없습니다. 또한, GPT의 결과는 사전 훈련된 데이터에 의존하기 때문에, 훈련 데이터에 편향이 포함되어 있을 수 있습니다. 요약하자면, GPT는 사전 훈련과 세부 조정을 통해 자연어 처리 작업을 수행하는 딥러닝 모델입니다. 사전 훈련된 GPT 모델은 문맥을 이해하고 자연스러운 텍스트를 생성할 수 있으며, 다양한 응용 분야에서 활용될 수 있습니다. 그러나 GPT는 몇 가지 제한사항이 있으며, 사용할 때 주의가 필요합니다.
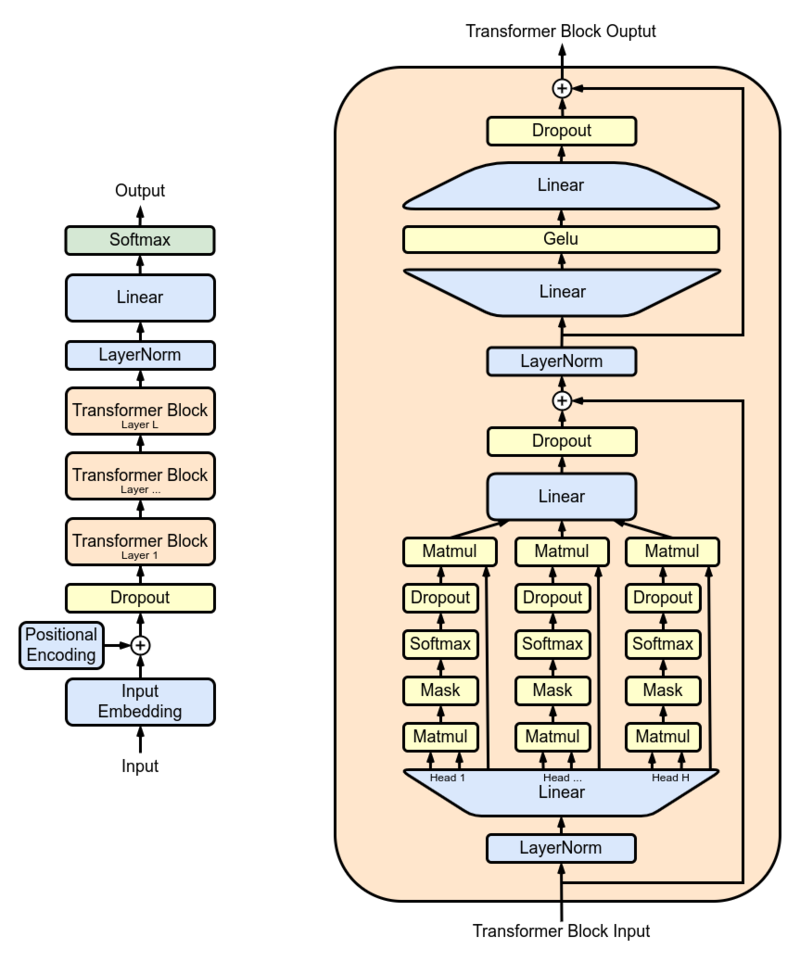
GPT의 개발 과정이 무엇인가요?
GPT의 개발 과정은 크게 사전 훈련(Pre-training)과 세부 조정(Fine-tuning)으로 구성됩니다.
- 사전 훈련 (Pre-training) 사전 훈련 단계에서 GPT는 대규모의 텍스트 데이터를 이용하여 사전 훈련됩니다. 이러한 텍스트 데이터는 웹 크롤링을 통해 수집되는 다양한 소스에서 가져올 수 있습니다. 대표적으로 위키피디아, 뉴스 기사, 소셜 미디어 등이 사용될 수 있으며, 이를 통해 GPT 모델은 언어에 대한 일반적인 지식을 배우게 됩니다. 사전 훈련 과정은 transformer 모델과 같이 self-attention 메커니즘을 기반으로 한 신경망 아키텍처를 사용합니다. GPT 모델은 문맥 정보를 이해하기 위해 문장 내부에서 단어 간의 상호작용을 학습하고, 입력 문장의 전반적인 의미를 파악하는 능력을 개발합니다.
- 세부 조정 (Fine-tuning) 사전 훈련된 GPT 모델은 세부 조정을 통해 특정 작업에 맞게 추가 학습됩니다. 세부 조정 단계에서는 특정 작업에 필요한 데이터셋을 이용하여 모델을 조정하고, 해당 작업에 대한 성능을 최적화합니다. 세부 조정은 비지도 사전 훈련 단계에서 학습한 언어의 일반적인 특징을 기반으로 하여 작업 특정 정보를 학습하는 과정입니다. 세부 조정 단계에서는 작업에 맞는 손실 함수를 정의하고, 해당 작업에 최적화되도록 모델의 파라미터를 업데이트합니다. 작업에 따라 입력 데이터가 다르고, 모델의 구성 및 파라미터 업데이트 방식도 다를 수 있습니다. 세부 조정을 통해 GPT 모델은 특정 작업에 대해 더 높은 정확도와 효과적인 결과를 제공할 수 있습니다.
요약하면, GPT의 개발 과정은 사전 훈련과 세부 조정으로 구성됩니다. 사전 훈련 단계에서 GPT는 대규모의 텍스트 데이터를 이용하여 언어 모델을 사전 학습합니다. 그 후, 세부 조정을 통해 특정 작업에 맞게 모델을 추가 학습하여 해당 작업에 최적화된 결과를 얻을 수 있습니다.
'Artificial Intelligence(인공지능)' 카테고리의 다른 글
| AIoT: Google Nest으로 스마트 홈을 (0) | 2023.07.04 |
|---|---|
| LLM(Large Language Models): AI의 대화 능력, LaMDA가 만들어낸 혁명 (0) | 2023.07.03 |
| MLOps: 데이터 버전 관리를 위한 혁신, DVC(Data Version Control) (0) | 2023.07.01 |
| MLOps: 머신러닝을 동시에 간편하게 Kubeflow (0) | 2023.06.29 |
| OpenAI: 미래를 열어가는 혁신적인 생성 AI 기술 (0) | 2023.06.26 |