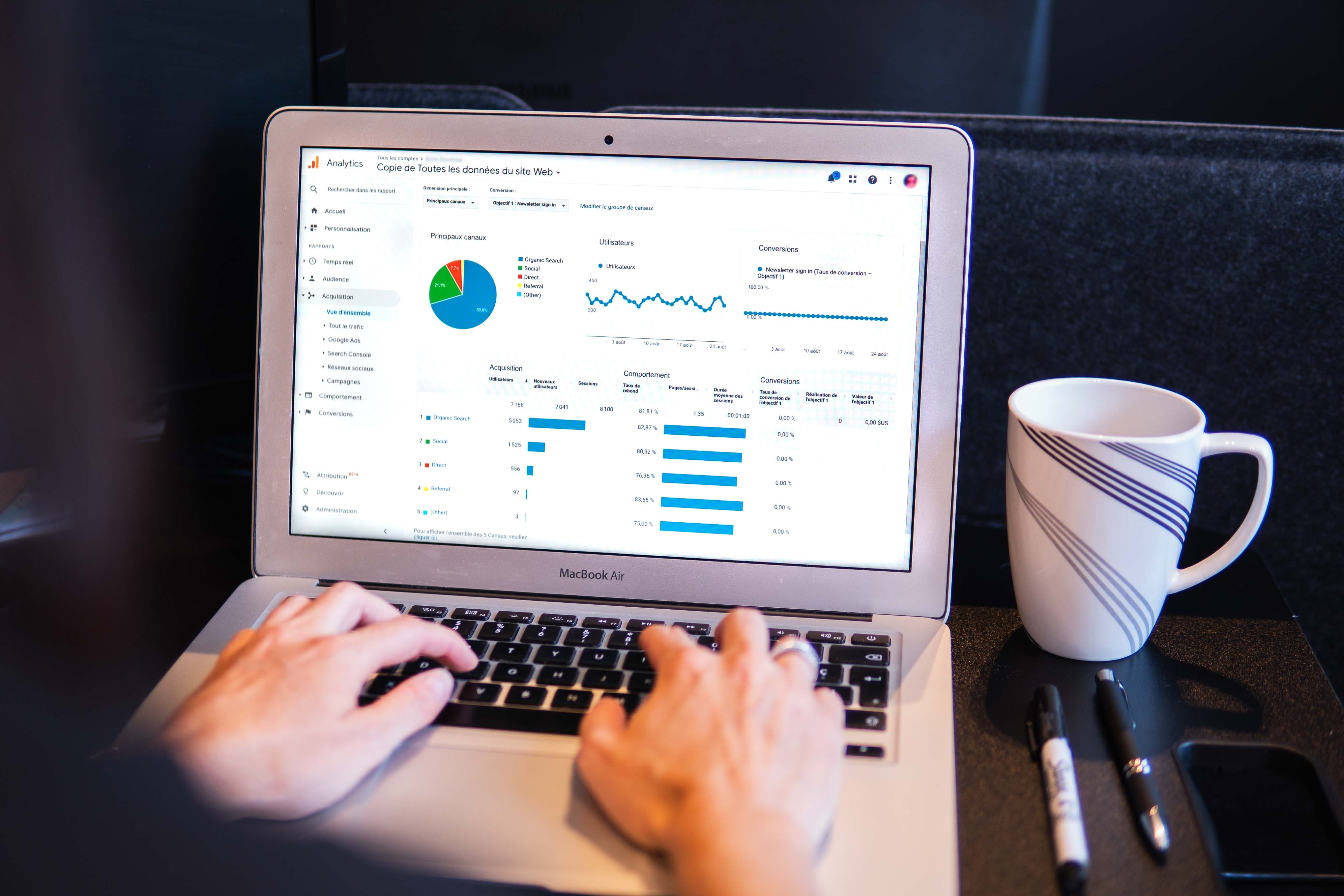
기계학습에서는 대량 및 다양한 데이터를 사용하여, 데이터를 분류, 예측, 회귀, 군집화 등의 방법으로 분석함으로써 모델을 만듭니다. 핵심적인 데이터 수집 단계에서는, 해당 분야에서 필요한 학습 데이터를 구성해야 합니다. 이러한 데이터 셋은 일반적으로 비정형 데이터 형식을 가지며, 이미지, 텍스트, 오디오, 비디오 등 다양한 정보를 제공합니다. 이 학습 데이터를 구성함으로써, 모델은 이러한 데이터를 기반으로 예측, 분류, 회귀 등의 작업을 수행합니다.

데이터 수집의 기술 노하우는 크롤링, 스크래핑, 수작업 데이터 입력, 데이터 정제 등을 통해 이루어집니다. 그러나, 수작업으로 직접 데이터를 생성해야 하는 경우 또는 적은 데이터가 있는 경우가 있으며, 이러한 경우 추가적인 비용과 시간이 들어갑니다.
현재 데이터 수집의 동향으로는, 향상된 자동화 기술이 적용된 데이터 레이블링, 드론 또는 IoT 장치를 사용한 데이터 수집 등 다양한 분야에서 이루어지고 있습니다. 이러한 기술의 상용화에 따라, 데이터 수집 및 관리 기술력이 점차 향상되고 있으며, 데이터 수집 작업에 대한 비용과 효율도 향상되고 있습니다.
데이터 수집을 위한 모델은 분야와 데이터 형태, 수집 방법에 따라 크게 다릅니다. 각 분야에서 사용되는 대표적인 모델로는, 이미지 데이터 수집을 위한 "Google Image Scraper", 텍스트 및 웹 데이터 수집을 위한 'beautifulsoup' 등의 모듈이 있습니다. 기계학습 라이브러리 중 'scikit-learn', 'TensorFlow' 등도 데이터 수집 모듈이 포함되어 있습니다.
먼저 "Google Image Scraper"의 소스코드 예시입니다.
# 필요한 라이브러리 import하기
from google_images_download import google_images_download
이미지 다운로드를 위한 클래스 생성
class ImageDownloader:
# 생성자 함수
def init(self, keyword, path, number):
self.keyword = keyword
self.path = path
self.number = number
self.image_download()
# 이미지 다운로드 함수
def image_download(self):
# 이미지 다운로드에 필요한 설정
self.response = google_images_download.googleimagesdownload()
self.arguments = {"keywords": self.keyword, "limit": self.number, "print_urls": True, "no_directory": True, "output_directory": self.path}
self.paths = self.response.download(self.arguments)
테스트용 코드
if name == 'main':
scraper = ImageDownloader("cat", "/download_path", 10)
이 코드는 google_images_download 라이브러리를 사용하여, cat라는 키워드를 가진 이미지를 /download_path 경로에 10장 다운로드합니다.
다음은 텍스트 및 웹 데이터 수집을 위한 'beautifulsoup' 모듈의 소스코드 예시입니다.
# 필요한 라이브러리 import하기
import requests
from bs4 import BeautifulSoup
텍스트 다운로드 함수
def get_text(url):
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
articles = []
for article in soup.select('div.article'):
articles.append(article.text.strip())
return articles
테스트용 코드
if name == 'main':
url = 'https://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=105&oid=001&aid=0011031389'
articles = get_text(url)
print(articles)
이 코드는 requests와 beautifulsoup 라이브러리를 사용하여, 네이버 뉴스 페이지에서 텍스트를 수집해 리스트로 반환합니다.
마지막으로 'scikit-learn', 'TensorFlow' 등도 데이터 수집 모듈의 소스코드 예시를 작성해드리겠습니다.
# Scikit-learn
from sklearn.datasets import load_iris
데이터 로드하기
iris = load_iris()
데이터 정보 출력하기
print(iris.DESCR)
TensorFlow
import tensorflow as tf
from tensorflow.keras.datasets import mnist
데이터 로드하기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
데이터 확인하기
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
위의 코드에서 처음으로 나오는 'Scikit-learn'에서는 'load_iris' 함수를 사용하여, iris 데이터셋을 로드합니다. 이 후 DESCR 속성으로 데이터셋 정보를 출력할 수 있습니다. 두 번째로 나오는 'TensorFlow'에서는 'mnist' 데이터셋을 불러옵니다. 이 데이터셋은 이미지 데이터로, load_data 함수를 통해 로드할 수 있습니다. 로드된 데이터셋은 x_train, y_train, x_test, y_test에 각각 할당됩니다. 마지막으로 이러한 데이터셋의 크기를 확인하기 위해, shape 함수를 사용하여 출력합니다.
하지만 데이터의 신뢰성과 일관성을 유지하기 위해서는, 데이터 수집 과정에서 주의할 사항들이 많습니다. 이러한 이유 때문에, 데이터 수집은 시간과 비용이 많이 들어가는 작업 중 하나입니다. 이러한 기술적 문제를 해결함으로써, 더욱 손쉬운 데이터 수집 및 관리가 가능한 환경을 조성하여, 다양한 분야의 인공지능 응용 사례들을 더욱 확장하고, 기계학습 모델의 효율성과 정확성을 향상할 수 있을 것입니다.
'Artificial Intelligence(인공지능)' 카테고리의 다른 글
| AI를 위한 모델 학습: 기계학습 3편 (0) | 2023.05.17 |
|---|---|
| AI를 위한 데이터 준비: 기계학습 2편 (0) | 2023.05.17 |
| 기계학습(머신러닝) - 기초적인 개념과 과정 (1) | 2023.05.17 |
| 기계학습(머신러닝) : 윤리적 고려? (0) | 2023.05.16 |
| 우리 삶을 변화시키는 기술: 머신 러닝, 딥 러닝, 자연어 처리 (0) | 2023.05.16 |