안녕하세요? 허니입니다. 운영체제의 프로세스의 처리 속도를 어떻게 하면 성능 효과를 볼 수 있을까요? 하드웨어는 고정된 성능과 자원을 제공하기 때문에 이를 효과적으로 활용하는 것이 프로세스의 처리 속도를 향상시키는 키가 될 수 있습니다. 이번 주제는 프로세스 관리가 어떻게 되는지를 알아야 이해하실 수 있으니 프로세스 관리에 대해 먼저 선행 스터디를 하시고 읽어주세요.
오늘의 주제
![]()
Process의 처리속도를 높이고 싶다면
|
CPU의 직렬연결과 병렬연결 비교 |
|
커널 스택 |
만약 하나의 컴퓨터 시스템에 3개의 CPU를 설치한다면 처리속도 역시 3배로 빨라질까
컴퓨터의 사용영역이 계속 확대되면서 사용자들은 좀 더 빠른 처리속도를 원하게 되었다. 많은 전문가들은 보다 빠르게 보다 많은 양의 작업을 처리하기 위해 여러 방법을 고려했다. 그 중 한가지 방법이 바로 CPU의 개수를 늘리는 것이었다. 그러나 CPU의 개수를 늘려 놓았는데도 처리속도가 빨라지지 않아 한때 시스템 설계자들은 매우 의아해하였다. 그렇다면 무엇이 문제였을까. 컴퓨터에 있어서 인간의 두뇌와 같은 CPU의 개수가 처리능력에 향상을 가져오지 못하다니 말이다. 바로 각각의 CPU가 처리해야 할 작업을 나누어 놓지 않았기 때문이었다. 다음과 같은 예를 하나 들어보자. 어느 컴퓨터 내부에 3개의 CPU를 설치해 놓았다고 생각해보자. 이 3개의 CPU가 처리해야 하는 계산은 총 30번인데 1번의 계산에 1초씩의 시간이 걸린다. A의 시스템에서는 3개의 CPU 설치 이후 더 이상의 조절작업을 하지 않아 CPU가 직렬연결 상태라면 30번의 계산은 다음 그림과 같이 수행된다. 그렇기 때문에 CPU가 하나인 컴퓨터 시스템과 계산속도의 차이가 없는 결과가 나타나게 되는 것이다.

그림 5 CPU의 직렬연결
바로 CPU가 1개이건 2개이건 작업이 일렬로 처리될 때는 속도에 별다른 차이가 없는 것이다. 바로 주어진 작업을 CPU마다 병렬처리로 조정해 놓아야만 3개의 CPU가 10개씩의 계산을 분담해 동시 처리가 가능해 지는 것이다. 다시 말해 30초의 작업시간이 10초로 빨라질 수 있는 것이다. 다음의 그림과 같이 말이다.

그림 6 CPU의 병렬연결
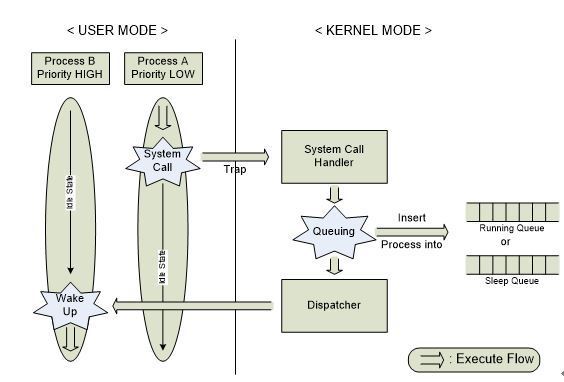
그러나 컴퓨터 시스템의 처리속도를 높이는 것과 관련된 문제는 여기서 끝나지 않았다. CPU가 2개 이상일 때 이것을 통해 동시에 수행되는 프로세스를 운영체제 구조적으로 뒷받침해줄 수 없는 것이다. 그것은 바로 커널 스택이 하나라는 OS구조상의 문제가 표면으로 나타난 것이다. 사용자영역의 프로세스들이 커널 스택의 사용을 위해서 차례를 기다려야 하는 것이다. CPU가 하나일 경우에는 커널 스택이 하나라는 것이 작업을 수행되는데 걸림돌로 작용하지는 않았었다. 그러나 CPU가 3개일 때 3개의 프로세스가 동시 처리가 가능해진다면 어떨까. 이를 구체적으로 설명하기 앞서 스택의 역할을 살펴보기로 하자. 메모리를 쪼개어보면 다음과 같은 process image가 나타난다.

그림 7 Process Image
스택은 프로그램이 수행되기 위한 모든 정보를 갖고 있는 부분으로 프로세스가 수행되는 동안 계속해서 변화되는 수행값을 저장하기 위해 메모리 확보를 하게 된다. 또한 스택포인터라는 것은 가장 최근 스택에 삽입된 자료의 위치를 가리키고 있는 포인터를 말한다.
포인터란 어떤 하나의 자료가 저장되어 있는 메모리의 위치 또는 주소를 가르키는 정보를 말한다. 프로그램에서는 이러한 정보를 통하여 자료가 저장되어 있는 위치로 직접이동할 수 있다. |
예를 들어 97년 한 해 동안 A라는 학생은 국어시험에서 다음과 같은 성적을 얻었다.
* 1학기 중간고사 80점, 기말고사 90점
* 2학기 중간고사 70점 기말고사 100점
총 평균 점수를 계산하는 프로그램을 수행한다면 그 수행과정에서 스택은 어떤 역할을 할까. 평균점수를 얻어내기 위해선 4번의 시험점수를 더하는 처리와 최종적으로 더한 값을 4로 나누는 작업이 이뤄져야 한다. 이 작업을 1학기 점수를 계산하는 프로세스 1과 2학기 점수를 계산하는 프로세스 2로 나누어 수행한다고 생각해보자. 프로세스 1이 계산한 80+90=170에서 170이라는 결과값이 바로 스택에 기억되어 다음 처리를 가능하게 해주는 것이다. 170이라는 점수가 저장되어 있어야만 프로세스2에 의해 2학기의 국어성적을 더할 수 있기 때문이다. 스택은 프로세스가 계산을 수행할 때마다 메모리를 확보해 임시 변수들을 저장하는 공간이다.

그림 8 스택의 역할
data segment : 작업을 처리하기 위한 자료(하나의 사실이나 숫자 통계치)등의 함수를 갖고 있는 부분으로 내용의 값을 디스크에서 가져온다. |
여기에서 잠깐 함수라는 개념을 짚어보자.
우리가 그림 2-9에서 A학생의 국어 평균점수를 계산해 보았다. 그렇다면 고려고등학교 모든 학생의 평균국어성적을 계산해 본다면 어떨까. 뭔가 보다 간편한 처리가 있어야 할 것 같지 않은가. 함수를 정의해 보자면 프로그램 내에서 자주 쓰는 기능들을 좀더 편리하게 사용할 수 있도록 정의해 놓은 것이다. 함수는 프로그래머의 의도에 따라 정의되기도 하고 이미 다른 사람에 의해 정의된 함수가 사용되기도 한다.
text segment code : 컴퓨터 시스템이 이해할 수 있는 기계어 부분으로 내용의 값을 디스크에서 가져온다. 모든 컴퓨터의 기본적인 언어는 0과 1의 배열로 이루어져 있다. data를 처리하기 위해 CPU를 가동시키려면 프로그램은 기계어 형태로 되어있어야 한다. 우리가 어디선가 들어 봤음직한 어셈블리어가 바로 이러한 기계어들인 것이다.

질문) 프로그램을 수행하다 만약 스택 영역이 부족해지면 어떻게 될까.

답) 이러한 경우 커널에 의해 자동처리가 된다. 스택으로 할당받은 공간이 가득 차서 스택 포인터가 그 범위 바깥을 접근하게 되면 자동적으로 segmentation fault가 생기고 이렇게 되면 커널이 모자라는 스택 영역을 보충해준다.
지금까지 스택의 역할을 살펴보았다. 그렇다면 앞서 언급한 커널 스택의 문제를 다시 짚어보자. 여러 개의 CPU가 사용되고 있는 경우 커널스택이 하나라면 어떤 일이 발생할까. 예를 들어 벽돌 쌓는 작업을 하는 인부는 여러 명인데 벽돌을 나르는 인부는 1명뿐이라고 가정한다면 어떨까. 벽돌 나르는 인부가 가져다준 벽돌을 모두 쌓은 후 다시 나에게 벽돌이 돌아올 순서가 오지 않는다면 그는 어쩔 수 없이 손을 놓고 있어야 함으로 작업 진척이 더딜 것이다. 마찬가지로 하나의 CPU만이 스택을 사용하게 됨으로 계속 수행-멈춤-수행-멈춤을 반복할 수밖에 없는 것이다. 다시 말해 자신이 작업할 영역을 확보해 줄 때까지 CPU는 아무 일도 할 수 없는 상황인 것이다.

그림 9 커널 스택이 하나일 경우
요점정리

작업의 처리속도를 높이기 위해서는 CPU가 1개이건 2개이건 작업이 일렬로 처리될 때는 속도에 별다른 차이가 없는 것이다. 바로 주어진 작업을 CPU마다 병렬처리로 스케줄 해놓아야만 동시 처리가 가능해 처리속도가 향상된다.
CPU 병렬 연결만 해놓으면 속도 향상의 모든 문제는 해결되나?
CPU가 2개 이상일 때 운영체제 구조상의 문제가 어려움으로 발생되었다. 그것은 바로 커널 스택이 하나라는 OS 구조상의 문제가 표면으로 나타난 것이다. CPU가 하나일 경우 커널스택 역시 하나이기 때문에 작업이 수행되는데 걸림돌이 존재하지 않지만 만약 CPU가 3개여서 3개의 프로세스가 동시 처리가 가능해진다면 어떨까. 사용자영역의 프로세스들이 커널 스택의 사용을 위해서 차례를 기다려야 하는 것이다.
커널 스택 문제의 해결 방안은?
커널 내의 스택이 하나이기 때문에 처리속도가 떨어지는 것을 걱정한 시스템 설계자는 커널스레드를 구상하기 시작했다. 바로 커널스레드 각자가 스택을 가짐으로써 처리속도가 증대되는 것이다.
|
목 차 |
|
운영체제 메모리 관련해서 알아야 할 개념은 어떤것이 있나요? (TLB, Locality, Working Set, Overlay) |
|
운영체제 디스크 공간 할당(Disk Space Allocation) 알고리즘과 효과적 알고리즘의 판단 기준은? |
|
|
'Past Material' 카테고리의 다른 글
| 운영체제 스케줄링 (Scheduling)은 어떻게 하나요? (0) | 2019.05.13 |
|---|---|
| 운영체제 스레드(Thread)는 무엇인가요? (0) | 2019.05.13 |
| 운영체제 프로세스 관리(Process Management)는 어떻게 하나요? (0) | 2019.05.13 |
| 운영체제 프로세스 생애주기(Process Lifecycle)에 대해서 (1) | 2019.03.22 |
| 운영체제를 이해하기 위해 필요한 기본 개념들 (0) | 2019.03.20 |
 잠깐, 상식!
잠깐, 상식!

















 OS의 필요성
OS의 필요성

 Handles
Handles
