안녕하세요? 허니입니다. 운영체제에서는 스케줄링 정책을 어떻게 하냐에 따라 효율적인 자원 분배를 할 수 있고, 상황에 따라 쓰이는 스케줄링 기법들이 모두 다르기 때문에 운영체제 설계할때 가장 어려운 부분입니다. 때문에 스케쥴링에 대해 잘 알아야 운영체제 정책 및 설계를 잘 할 수 있습니다. 학생이나 연구원분들에게 많은 도움이 될 것이라고 생각하여 포스팅을 시작하며 언제든지 질문은 환영입니다.
오늘의 주제
- 좋은 스케줄링이란?
- 프로세스 스케줄링 알고리즘은?
|
FCFS |
|
Priorty Scheduling |
|
Round Robin |
|
Multiple queue |
|
Shortest job first Scheduling |
스케줄링 (Scheduling)
우리가 살아가는데 스케줄이라는 건 왜 필요할까?
24시간 주어진 하루를 헛됨 없이 보다 알차게 보내기 위해 우리는 스케줄을 짠다. 프로세스 역시 알찬 일정을 수행하기 위해선 적절한 기준에 맞춘 스케줄링이 필요한 것이다.
 프로세스 스케줄링이란?
프로세스 스케줄링이란?
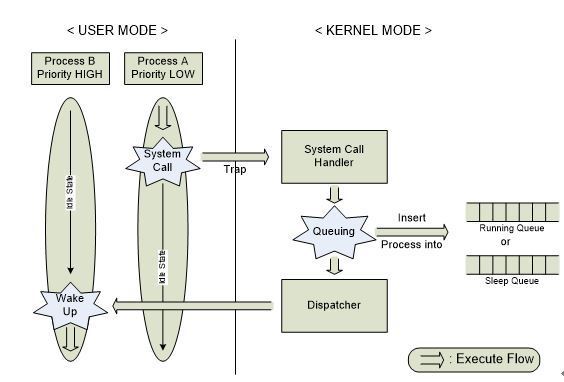
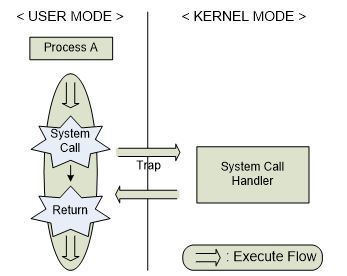
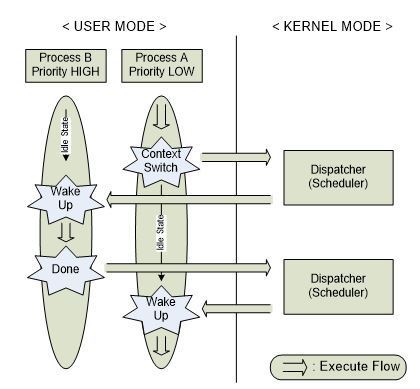
프로세스 스케줄러의 임무는 바로 준비, sleep, 실행 등의 상태에 놓인 프로세스들을 주어진 조건에 교체함으로써 CPU에 의해 보다 효율적으로 처리되도록 하는 것이다. 이와 같은 임무를 수행하기 위해서 프로세스 스케줄러가 해야 할 일은 우선 모든 프로세스의 상태를 파악하는 일이다. 프로세스의 상태 파악 후 프로세스가 준비 상태이면 준비 queue에, sleep 상태이면 sleep queue에 분배하는 작업을 하게 된다. 앞서 Process Life Cycle에서 언급되었던 것처럼 프로세스의 각 상태를 알기 위해 각각의 상태마다 리스트가 마련된다. 준비리스트에 놓인 프로세스는 각각 우선순위가 주어져 가장 높은 우선 순위의 프로세스의 차례로 CPU를 차지하게 된다. 그러나 sleep 리스트는 순위가 없다. 왜냐하면 sleep 상태에서 벗어나는 것은 정해진 순위에 의해서가 아니라 sleep상태로 머물러야 했던 조건들이 해결되면 다시 실행 상태로 돌아가기 때문이다. 이처럼 서로 다른 사이클로 프로세스들이 운영되기 때문에 프로세스 스케줄링이 필요한 것이다. Dispatcher는 프로세스 스케줄러에 포함된 하나의 요소로서 프로세스 스케줄러에 의해 선택된 프로세스에 CPU를 할당하는 기능을 하며 이때 프로세스의 여러 정보들을 레지스터에 적재(load)하고 프로세스 처리가 새로이 시작될 때 올바른 위치로 가게 해준다. 예를 들어 sleep 단계에 놓인 프로세스들을 sleep queue로 모아주는 작업이 바로 Dispatcher에 의해 수행되는 것이다.
레지스터(register)란? 컴퓨터의 CPU에서 사용되는 고속의 기억장치. CPU에서 연산을 수행하기 위해서는 반드시 피연산자가 레지스터에 존재해야 한다. 일반적으로 레지스터의 개수가 많을수록 처리속도가 빨라진다. 그러나 레지스터를 구현하는 비용이 많이 들기 때문에 일정수의 레지스터를 구현하게 된다. |
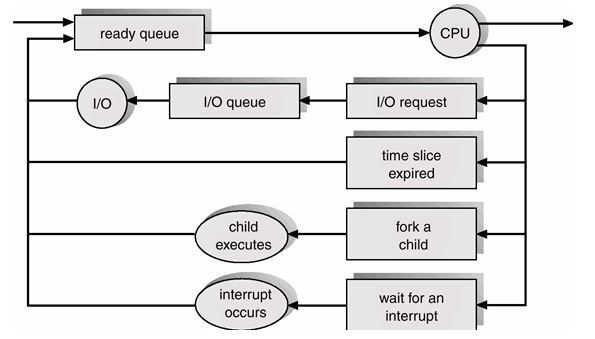
그림 16 프로세스 스케줄링
그렇다면 좋은 프로세스 스케줄링 정책이란 어떤 것 일까.
|
l CPU를 쉼 없이 100% 가동되게 함으로써 CPU의 효율을 최대화한다. l 주어진 시간 내에 가능한 많은 작업들을 실행함으로써 throughput(처리량)을 최대로 한다. l 빠른 대화식 요청에 의해 응답시간을 최소화한다. l 전체작업이 시스템으로 빨리 들어오고 나가게 함으로써 경과시간을 최소화 한다. l 가능한 빨리, 준비상태 큐로부터 작업들을 나오게 함으로써 대기시간을 최소화한다. l 모든 사람에게 CPU와 I/O의 시간을 똑같이 할당함으로써 모든 작업들에게 공정성을 보장한다. |
위의 모든 조건을 갖추게 할 수 있는 시스템 설계자가 있다면 그 사람은 분명 세상에서 가장 완벽한 설계자일 것이다. 그러나 안타깝게도 이러한 모든 조건이 충족되는 프로세스 스케줄링은 확실히 불가능하다. 시스템 설계자는 어느 조건을 만족시키는 것이 좋은 스케줄링인가를 판단해 그에 적절한 스케줄링 알고리즘을 선택하게 되는 것이다.
프로세스 스케줄링 알고리즘
어떤 문제가 우리 앞에 주어졌을 때 그것을 풀기 위한 절차가 필요하다. (절차라는 것은 이미 일정한 처리의 순서가 마련되어 있는 것을 말한다.) 병원을 찾으면 우선 접수를 하고 접수순서에 따라 의사를 기다리고 진료를 받고 약을 짓고 마지막으로 진료비를 납부하게 되면 된다. 그러나 이 한가지의 절차만 존재한다면 병원은 아마도 환자들의 불만을 항상 들어야 했을 것이다. 초를 다투는 응급 환자의 발생시 또한 진료시간이 끝난 후 환자 발생시를 위해 응급실이라는 별도의 환자처리방법을 만들어 놓았다. 프로세스 스케줄링 알고리즘 역시 단순히 하나의 방법만이 쓰이는 것이 아니라 알고리즘에 문제가 발생하게 되면 그것을 보안해 나가며 계속 발전해 나가고 있는 것이다. “프로세스들이 어떤 절차를 통해 처리되어질 것인가” 하는 것을 알고리즘이라고 한다. 프로세스들은 다음과 같은 알고리즘에 의해 수행된다.
![]()
FCFS (First Come First Served)
말 그대로 먼저 도착한 프로세스를 먼저 처리하는 방법이다. 이 방법의 가장 큰 장점은 구현하기가 쉽다는 것과 공평하다는 것이다. 그러나 가장 뒤에 들어온 프로세스가 가장 시급한 업무를 갖고 있다면 어떨까. 그 시급한 업무는 두발을 동동 구르며 안타까워하지 않을까. 바로 이러한 문제가 발생했을 경우 FCFS는 속수무책인 것이다. 또한 긴 작업이 짧은 작업을 기다리게 할 경우 평균 처리 시간이 휠씬 느려진다. 간단한 예를 한번 들어보자.
예제) job A = 7초, job B = 3초, job C = 2초
처리1. A -> B -> C
7초 10초 12초
평균 처리 시간= 7 + 10 + 12 / 3 = 9.666...
처리1. A -> B -> C
2초 5초 12초
평균 처리 시간= 2 + 5 + 12 / 3 = 6.333...
위의 예에서 살펴 보았듯이 A, B, C 작업의 총 처리 시간은 12초로 처리1과 처리2과가 똑같다. 그러나 7초의 긴 시간이 소요되는 작업이 앞에 놓인 처리1의 경우 평균처리시간이 9.666초인데 비해 처리2에 경우 6.333의 평균처리시간이 소요되었다.
![]() Priority Scheduling (우선순위 스케줄링)
Priority Scheduling (우선순위 스케줄링)
이 알고리즘은 중요한 작업들에 우선권을 주어 우선순위가 가장 높은 작업을 먼저 처리하도록 하는 방법이다. 그렇다면 과연 어떤 조건을 가진 작업들이 우선순위를 갖는가. 그것은 시스템 설계자의 자유의지이지만 다음과 같은 보편적인 기준이 있다. 외부적인 우선순위는 사용자의 제시에 따라 이뤄지는데 사용자가 작업처리비용을 더 지불하거나 최고경영자가 급히 처리해야 할 업무를 지시하는 경우로써 이러한 우선순위를 결정하는 것은 OS가 통제할 수 없는 것이다.
내부적인 요인에 따른 우선순위의 근거는 일반적으로 다음과 같다.
|
l 적은 양의 메모리를 요구하는 작업은 우선순위를 높게 큰 메모리를 요구하는 작업은 우선순위를 낮게 책정한다. l 많은 주변장치를 요구하는 작업은 우선순위를 낮게 적은 주변장치를 요구하는 작업들은 우선순위를 높게 책정한다. l 긴 CPU사이클을 요구하는 작업은 우선순위를 낮게 짧은 CPU 사이클을 요구하는 작업은 우선순위를 높게 책정한다. |
Priority Scheduling 의 단점으로는 우선순위에서 자꾸 밀려 영영 처리될 수 없는 프로세스가 생겨날 가능성이 있다는 것인데 이럴 때를 대비해 시스템 내에 오랫동안 머물렀던 작업들에게 우선 순위를 높여주는 aging 방법이 고안되었다.
![]() Round Robin
Round Robin
라운드로빈의 특징은 하나의 작업에 의해서 CPU가 독점되지 않도록 타임퀀텀을 정해 놓고 타임퀀텀을 다 쓰고 나서도 처리가 끝나지 않으면 그 작업을 준비상태 큐의 맨 뒤로 놓이게 하는 방법이다. 이 방법은 FCFS 스케줄링 방법을 보완해준 것으로 예 2-1에서 설명했듯이 처리시간이 긴 작업이 앞자리를 차지하고 있을 경우 평균 처리 시간이 길어져 작업처리가 효율적이지 못한 경우에 많은 도움이 된다. 라운드로빈의 성능은 타임퀀텀 크기에 큰 영향을 받는다. 극단적으로 타임 퀀텀이 매우 크다면 라운드로빈은 FCFS와 다를 바가 없는 것이다. 다시 말해 타임퀀텀의 크기가 증가되면 response time이 길어지고 타임퀀텀이 감소하면 response time이 짧아진다.
간단한 예를 하나 들어보자.
예제)
다음과 같은 처리시간을 요구하는 작업의 경우
a=5초, b=3초, c=1초
타임퀀텀 1초일 때 c의 response time은 얼마일까.
a 1초, b 1초, c 1초 => response time : 3초
타임퀀텀 2초일 때 c의 response time은 얼마일까.
a 2초, b 2초, c 1초 => response time : 5초
![]() Multiple queue
Multiple queue
공통적인 특성을 가진 작업들끼리 모아 서로 다른 클래스로 구성하여 클래스마다 각각의 queue를 구성하는 것을 Multiple queue라고 한다. 예를 들어 카메라를 통한 실시간 동영상 입력을 컴퓨터 시스템이 받아드리는 경우와 웹브라우저를 통해 자료를 전송받는 것은 대단한 차이가 있는 작업이다. 카메라 입력의 경우 1초라도 시간을 놓쳐버리면 데이터가 망가져 버리는 것은 너무도 당연한 노릇이다. 그러나 웹브라우저를 통한 자료 전송은 전송이 중간에 끊어지면 재전송을 실행해도 큰 문제가 되진 않는다. 이와 같이 특성이 다른 작업을 하나로 모아 놓는다면 실수를 범하기가 쉬울 것이다. 그렇기에 Multiple queue를 통해 카메라 입력 작업과 웹브라우저 자료전송을 따로 따로 관리하게 되는 것이다.

그림 17 Multiple Queue
그러나 Multiple queue로 스케줄링을 할 경우 CPU가 하나일 때는 문제가 발생하게 된다. 바로 하나의 run queue만이 존재하므로 각기 다른 특성의 작업들을 수행해내기가 어려운 것이다. 5개의 Multiple queue가 구성되었다면 run queue 역시 5개가되어야지 서로 손발이 맞게 일이 처리되는 것이다.
![]() Shortest job first Scheduling
Shortest job first Scheduling
이 방법은 가장 짧은 시간에 처리될 수 있는 작업을 가장 먼저 수행하는 것이다. 그러나 이것은 이론만이 뒷받침 될 뿐 실행되기는 불가능하다. 하나의 프로세스가 얼마만큼의 작업을 해야 끝날지를 CPU는 알 수 없기 때문이다. 말 그대로 그것은 해봐야 안다.
요점정리
![]()
Scheduling
1) FCFS(First Come First Served)
먼저 도착한 프로세스를 먼저 처리하는 방법이다. 이 방법의 가장 큰 장점은 OS를 구현하기가 쉽다는 것과 공평하다는 것이다.
2) Priority Scheduing (우선순위스케줄링)
이 알고리즘은 중요한 작업들에 우선권을 주어 우선순위가 가장 높은 작업을 먼저 처리하도록 하는 방법이다.
3) Round Robin
라운드로빈의 특징은 하나의 작업에 의해서 CPU가 독점되지 않도록 타임퀀텀을 정해 놓고 타임퀀텀을 다 쓰고 나서도 처리가 끝나지 않으면 그 작업을 준비상태 큐의 맨 뒤로 놓이게 하는 방법이다.
4) Multiple queue
공통적인 특성을 가진 작업들끼리 모아 서로 다른 클래스로 구성하여 클래스마다 각각의 queue를 구성하는 것을 Multiple queue라고 한다.
5) Shortest job first Scheduling
가장 짧은 시간에 처리될 수 있는 작업을 가장 먼저 수행하는 것이다. 이 방법은 이론만이 뒷받침 될 뿐 실제적으로는 수행이 불가능하다.
|
목 차 |
|
운영체제 메모리 관련해서 알아야 할 개념은 어떤것이 있나요? (TLB, Locality, Working Set, Overlay) |
|
운영체제 디스크 공간 할당(Disk Space Allocation) 알고리즘과 효과적 알고리즘의 판단 기준은? |
'Past Material' 카테고리의 다른 글
| 운영체제 프로세스 동기화가 무엇인가요? (0) | 2019.05.13 |
|---|---|
| 운영체제 스케줄링 알고리즘의 비교 기준이 있나요? (0) | 2019.05.13 |
| 운영체제 스레드(Thread)는 무엇인가요? (0) | 2019.05.13 |
| 운영체제 프로세스(Process)의 처리 속도는 어떻게 높일까? (0) | 2019.05.13 |
| 운영체제 프로세스 관리(Process Management)는 어떻게 하나요? (0) | 2019.05.13 |












 잠깐, 상식!
잠깐, 상식!



















 Handles
Handles